
Kürzlich hat Tencent sein selbst entwickeltes Deep-Thinking-Modell – Hun Yuan T1 – offiziell veröffentlicht.
Hun Yuan T1 wurde auf Basis von großangelegtem verstärktem Lernen speziell für naturwissenschaftliche Herausforderungen in Mathematik, Logik, Wissenschaft und Programmierung optimiert, wodurch eine deutliche Verbesserung der Inferenzfähigkeit erzielt wurde. In gängigen Benchmarks wie dem MMLU-PRO Datensatz erzielte Hun Yuan T1 eine hervorragende Punktzahl von 87,2 und liegt damit knapp hinter dem Top-Modell o1. Auch in öffentlichen Benchmark-Tests wie CEval, AIME und Zebra Logic, die sich auf englisch- und chinesischsprachige Wissensfragen sowie wettbewerbsorientierte Mathematik- und Logikaufgaben konzentrieren, zeigt Hun Yuan T1 das Niveau eines branchenführenden Inferenzmodells.
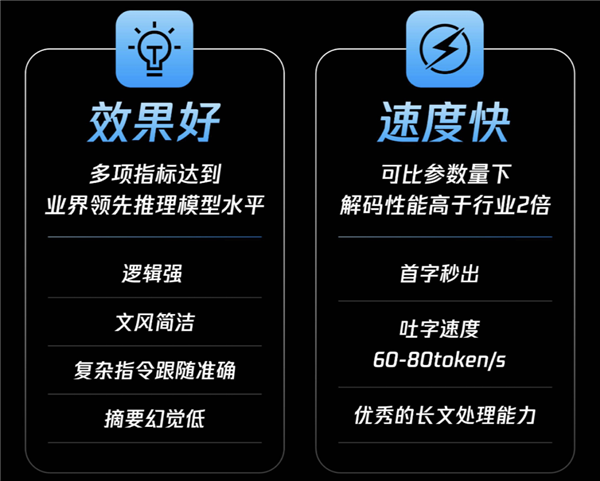
Neben den grundlegenden Inferenzfähigkeiten zeigt Hun Yuan T1 auch in verschiedenen Ausrichtungsaufgaben, Anweisungsfolgeaufgaben und Aufgaben zur Werkzeugnutzung eine sehr hohe Anpassungsfähigkeit. Dies ist dem innovativen Aufbau, der von Hun Yuan Turbo S übernommen wurde, und dem Hybrid-Mamba-Transformer-Fusionsmodus zu verdanken. Dies ist die erste Anwendung der Hybrid-Mamba-Architektur in der Industrie, die ohne Verlust auf ein extrem großes Inferenzmodell angewendet wird. Sie reduziert effektiv die Rechenkomplexität traditioneller Transformer-Strukturen, verringert den Speicherbedarf des KV-Cache und senkt so die Trainings- und Inferenzkosten deutlich.
Darüber hinaus kann Hun Yuan T1 aufgrund seiner hervorragenden Fähigkeit zur Erfassung langer Texte das in der Inferenz mit langen Texten häufig auftretende Problem des Verlusts von Kontextinformationen und der Abhängigkeit von Informationen über große Entfernungen effektiv lösen. Die Hybrid-Mamba-Architektur wurde speziell für die Verarbeitung langer Sequenzen optimiert. Durch effiziente Berechnungsmethoden wird bei gleichzeitiger Gewährleistung der Fähigkeit zur Erfassung langer Textinformationen der Ressourcenverbrauch deutlich reduziert. Bei einer ähnlichen Anzahl an Aktivierungsparametern verdoppelt Hun Yuan T1 die Decodiergeschwindigkeit.
Derzeit ist Tencent Hun Yuan T1 bereits erlebbar und ein API-Dienst wurde bereitgestellt. Benutzer können je nach Bedarf die Vorteile dieses leistungsstarken Inferenzmodells nutzen, mit einem Preis von 1 Yuan pro Million Tokens für die Eingabe und 4 Yuan pro Million Tokens für die Ausgabe.