Une avancée révolutionnaire dans le domaine de l'interaction vocale ! Step Audio, une entreprise chinoise d'IA, a récemment publié en open source un


Partage de cas de monétisation de l'IA
Cas de monétisation de la création d'images par l'IA
Cas de monétisation de la création de vidéos par l'IA
Cas de monétisation de la création audio par l'IA
Cas de monétisation de la rédaction de contenu par l'IA
Affiche le classement du nombre total de visites des sites web d'IA
Suit les sites web d'IA à la croissance la plus rapide en termes de trafic
Se concentre sur les sites web d'IA avec des baisses de trafic importantes
Affiche le classement hebdomadaire des visites des sites web d'IA
Classement du nombre total de visites des sites web de génération d'images par l'IA
Classement du nombre total de visites des sites web d'assistants personnels d'IA
Classement du nombre total de visites des sites web de génération de personnages par l'IA
Classement du nombre total de visites des sites web de génération de vidéos par l'IA
Projets IA populaires sur GitHub par nombre total d'étoiles
Projets IA populaires sur GitHub par taux de croissance
Classement des développeurs IA populaires sur GitHub
Classement des organisations IA populaires sur GitHub
Une avancée révolutionnaire dans le domaine de l'interaction vocale ! Step Audio, une entreprise chinoise d'IA, a récemment publié en open source un
Bienvenue dans la section [AI Quotidien] ! Voici votre guide pour explorer le monde de l'intelligence artificielle chaque jour. Chaque jour, nous vous présentons les points forts du domaine de l'IA, en mettant l'accent sur les développeurs, en vous aidant à comprendre les tendances technologiques et à découvrir des applications de produits IA innovantes.

Le groupe Yiwu Mall a annoncé l'intégration officielle du modèle linguistique géant Tongyi d'Alibaba. En combinant les avantages d'Alibaba dans le cloud computing, le big data et le commerce électronique, cette collaboration aidera 2,1 millions de petites et moyennes entreprises à utiliser l'IA pour une gestion précise et une expansion rapide sur les marchés étrangers. Ce partenariat marque une étape importante dans la transformation numérique et le déploiement mondial du groupe Yiwu Mall, et souligne le rôle crucial d'Alibaba dans la promotion de la transformation numérique des PME.

Manus, le produit Agent IA de la startup chinoise Monica, a récemment suscité un engouement sur la plateforme X. Son fondateur, Ji Yichao, a dévoilé aujourd'hui des détails techniques supplémentaires sur les médias sociaux. Selon Ji Yichao, Manus est développé sur la base du modèle linguistique géant Qianwen d'Alibaba, et utilise plusieurs modèles finement ajustés pour réaliser ses fonctionnalités uniques. Cette annonce a non seulement déclenché une discussion au sein de l'industrie sur l'origine technologique de Manus, mais a également ravivé l'intérêt de la communauté mondiale de l'IA pour son potentiel. Ji Yichao...

Bienvenue à la rubrique 【AI Quotidien】 ! Votre guide quotidien pour explorer le monde de l'intelligence artificielle. Chaque jour, nous vous présentons les sujets d'actualité du domaine de l'IA, en nous concentrant sur les développeurs, pour vous aider à comprendre les tendances technologiques et les applications innovantes des produits IA. Découvrez de nouveaux produits IA : https://top.aibase.com/1、Attention ! Foxconn espère prendre une place de choix dans la compétition mondiale de l'IA grâce à FoxBrain, et continuera d'optimiser les modèles pour relever les défis technologiques.

Selon le dernier classement publié par la communauté open source Hugging Face, le modèle linguistique géant Wanxiang d'Alibaba, lancé il y a seulement 6 jours, a dépassé DeepSeek-R1 pour atteindre la première place des deux classements importants, le classement des modèles populaires et le classement de l'espace des modèles. Cette réussite met non seulement en évidence les performances techniques exceptionnelles du modèle Wanxiang, mais reflète également sa large reconnaissance et son influence au sein de la communauté open source mondiale.

Baidu Search a subi une mise à jour majeure. Récemment, l'entrée 'Recherche IA' a été officiellement lancée sur sa page d'accueil Web. Cette fonctionnalité, issue d'une mise à niveau complète de l'assistant IA de Baidu Search, marque une nouvelle percée de Baidu dans le domaine de la recherche intelligente. Ce moteur de recherche IA pour ordinateur de bureau, basé sur le modèle linguistique géant Wenxin, a réalisé une intégration approfondie avec l'écosystème Baidu. En intégrant plusieurs plateformes de contenu telles que le moteur de recherche Baidu, Baidu Santé, Baidu Lvlin, Baidu Wenku et Baidu Éducation, la 'Recherche IA' peut fournir aux utilisateurs des résultats de recherche plus fiables et plus fiables.

State Grid Corporation of China a récemment annoncé le lancement du premier grand modèle d'intelligence artificielle de Chine pour le secteur de l'énergie électrique : le modèle Bright Power. Un accord-cadre de coopération stratégique a été signé avec Baidu Group et Alibaba Group. Les autorités ont indiqué qu'une collaboration entre les parties prenantes permettra de construire ensemble le modèle Bright Power, et de promouvoir l'innovation technologique et industrielle dans le secteur de l'énergie électrique.

Jieyue Xingchen a récemment annoncé le lancement de Step-1o, un nouveau modèle de synthèse vocale direct appartenant à la matrice de modèles Step. Il s'agit du premier modèle linguistique géant de synthèse vocale direct de 100 milliards de paramètres en Chine. Ce nouveau modèle marque une avancée majeure dans le domaine de la technologie vocale. Grâce à une solution vocale directe, il permet une intégration de la compréhension et de la génération de la parole, améliorant ainsi le QI et le QE du modèle et offrant une expérience de communication de haute qualité et hyperréaliste.

Anthropic et Hume AI ont récemment lancé une technologie d'interaction vocale innovante, visant à réaliser une interaction homme-machine plus naturelle et émotionnellement intelligente. Cette technologie combine les capacités de traitement du langage naturel de Claude et les fonctionnalités de reconnaissance émotionnelle d'EVI2, offrant de nouvelles perspectives pour les modes d'interaction avec les assistants numériques. La technologie clé, EVI2, est capable d'identifier les nuances émotionnelles dans la voix de l'utilisateur et d'adapter l'interaction en conséquence. Comparé aux assistants vocaux traditionnels, ce système améliore considérablement la fluidité et la personnalisation de l'interaction.

Google a officiellement lancé la nouvelle application Gemini sur l'App Store d'Apple, et introduit la fonction d'interaction vocale Gemini Live, marquant ainsi une avancée majeure dans le domaine des assistants vocaux intelligents. Simultanément, l'annonce d'Apple concernant l'intégration de ChatGPT d'OpenAI dans Siri souligne l'intensification de la compétition dans ce secteur. Version améliorée de Bard, lancé par Google en 2023, Gemini est...
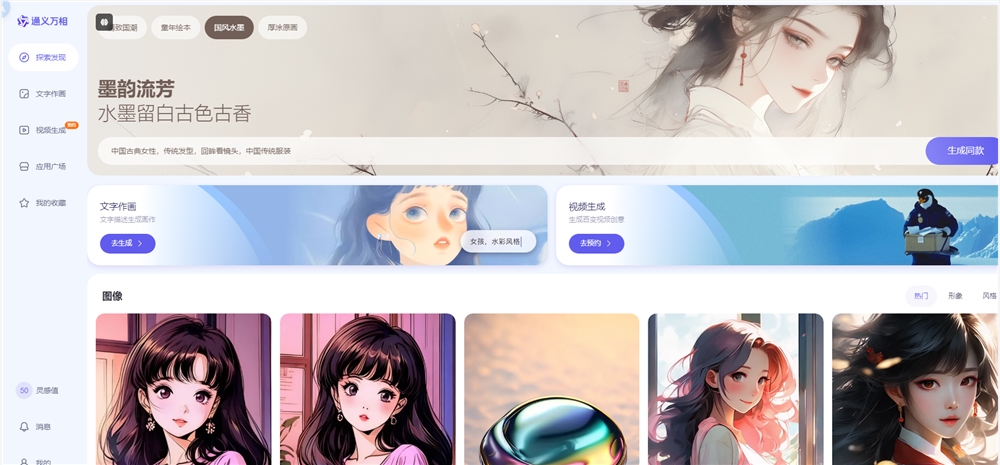
Alibaba Tongyi lancera son modèle linguistique géant de génération vidéo lors de la prochaine conférence Cloud Computing, suscitant un vif intérêt dans le secteur. Actuellement, des inscriptions pour la « génération vidéo » sont discrètement apparues sur la chaîne d'applications Tongyi et sur la version PC de Tongyi Wanxiang, mais la fonctionnalité n'est pas encore disponible. Selon les informations de la page, ce nouveau modèle linguistique géant de génération vidéo est développé en interne par le laboratoire Tongyi d'Alibaba et comprend deux modes de création principaux : « texte vers vidéo » et « image vers vidéo ». Les utilisateurs peuvent générer du contenu vidéo à partir de texte ou d'images. Ce lancement apportera sans aucun doute de nouvelles opportunités aux créateurs de contenu.