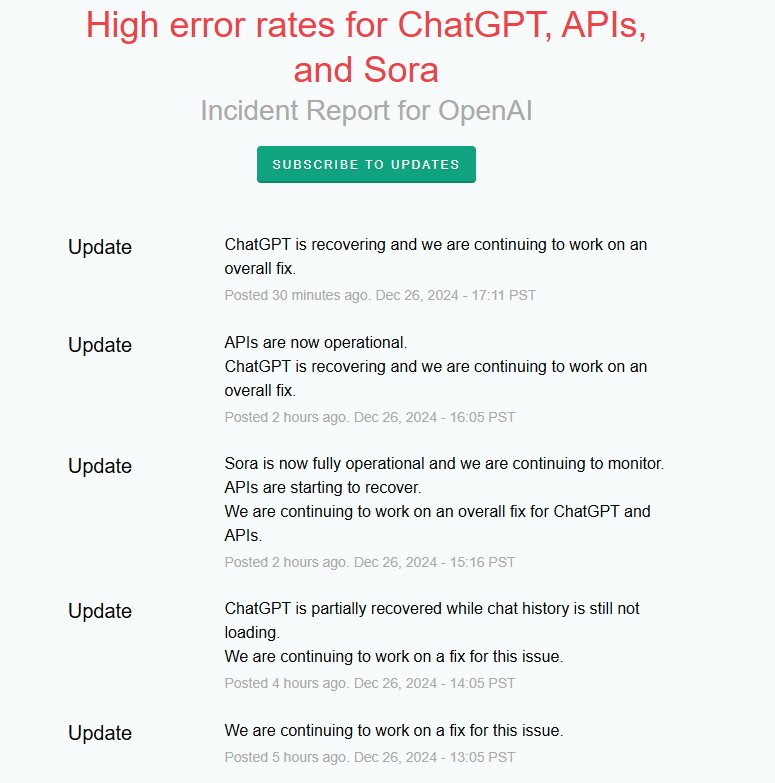
La semaine dernière (11 décembre), les services d'OpenAI tels que ChatGPT et Sora ont subi une panne de 4 heures et 10 minutes, affectant de nombreux utilisateurs. OpenAI vient de publier un rapport détaillé sur cette panne de ChatGPT.

En résumé, cette panne est due à une petite modification ayant eu des conséquences graves. Les ingénieurs se sont retrouvés bloqués hors du plan de contrôle, incapables de résoudre le problème à temps. Face à cette panne, les ingénieurs d'OpenAI ont rapidement mis en œuvre plusieurs actions correctives, notamment la réduction de la taille du cluster, le blocage de l'accès réseau à l'API de gestion Kubernetes et l'augmentation des ressources du serveur d'API Kubernetes. Après plusieurs tentatives, ils ont finalement récupéré l'accès à une partie du plan de contrôle Kubernetes et ont redirigé le trafic vers des clusters sains, permettant ainsi une restauration complète du système.
L'incident s'est produit à 15h12, heure du Pacifique. Les ingénieurs ont déployé un nouveau service de télémétrie pour collecter les métriques du plan de contrôle Kubernetes (K8S). Cependant, la configuration de ce service était involontairement trop large, entraînant l'exécution simultanée d'opérations gourmandes en ressources de l'API K8S sur chaque nœud de chaque cluster. Cela a rapidement conduit à la saturation des serveurs d'API, rendant la plupart des plans de données K8S des clusters inopérants.
Il est important de noter que, bien que le plan de données K8S puisse théoriquement fonctionner indépendamment du plan de contrôle, la fonctionnalité DNS dépend du plan de contrôle, empêchant ainsi la communication entre les services. La surcharge des opérations de l'API a endommagé le mécanisme de découverte de services, entraînant une panne totale du service. Bien que le problème ait été identifié en 3 minutes, l'incapacité des ingénieurs à accéder au plan de contrôle pour effectuer un rollback a créé une situation de « boucle infinie ». L'échec du plan de contrôle les a empêchés de supprimer le service défaillant et donc de procéder à la restauration.
Les ingénieurs d'OpenAI ont alors exploré différentes méthodes pour restaurer les clusters. Ils ont essayé de réduire la taille des clusters pour diminuer la charge de l'API K8S et de bloquer l'accès à l'API de gestion K8S afin de permettre aux serveurs de récupérer. Ils ont également augmenté les ressources du serveur d'API K8S pour mieux gérer les requêtes. Après plusieurs efforts, ils ont finalement repris le contrôle du plan de contrôle K8S, permettant de supprimer le service défaillant et de restaurer progressivement les clusters.
Pendant ce temps, les ingénieurs ont également redirigé le trafic vers des clusters sains, restaurés ou nouvellement ajoutés, afin de réduire la charge sur les autres clusters. Cependant, de nombreux services tentant de se restaurer simultanément, les limites de ressources ont été saturées, ce qui a nécessité des interventions manuelles supplémentaires et a allongé le temps de restauration de certains clusters. Grâce à cet incident, OpenAI espère tirer des leçons pour éviter de se retrouver à nouveau « enfermé » en cas de situation similaire à l'avenir.
Détails du rapport : https://status.openai.com/incidents/ctrsv3lwd797
Points clés :
🔧 Cause de la panne : Une petite modification du service de télémétrie a entraîné une surcharge des opérations de l'API K8S, provoquant une panne de service.
🚪 Difficulté des ingénieurs : La panne du plan de contrôle a empêché les ingénieurs d'y accéder, les empêchant de résoudre le problème.
⏳ Processus de restauration : La restauration du service a été effectuée grâce à la réduction de la taille des clusters et à l'augmentation des ressources.