
Récemment, Tencent a officiellement lancé son propre modèle de réflexion approfondie : HunYuan T1, version officielle.
La version officielle de HunYuan T1, basée sur un apprentissage par renforcement à grande échelle, a été optimisée pour les problèmes scientifiques difficiles, notamment les mathématiques, le raisonnement logique, les sciences et le code. Cela a permis d'améliorer considérablement ses capacités de raisonnement. Dans les benchmarks courants, tels que le jeu de données amélioré d'évaluation des grands modèles linguistiques MMLU-PRO, HunYuan T1 a obtenu un excellent score de 87,2, juste derrière le modèle de pointe o1. De plus, dans des tests de référence publics tels que CEval, AIME et Zebra Logic, couvrant les connaissances en chinois et en anglais ainsi que les mathématiques et le raisonnement logique de niveau compétition, HunYuan T1 a démontré un niveau de raisonnement de pointe dans le secteur.
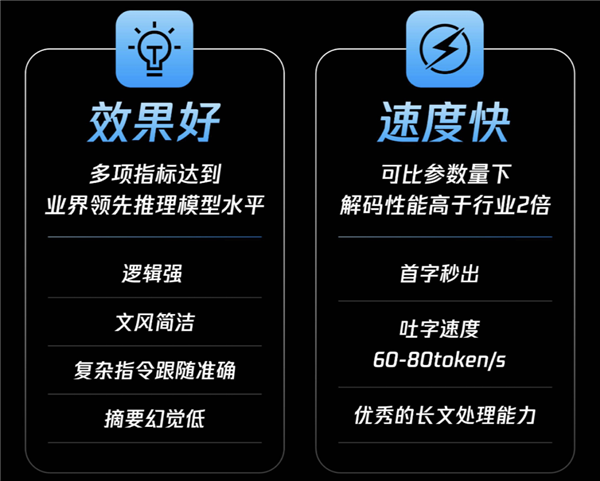
Au-delà de ses capacités de raisonnement de base, la version officielle de HunYuan T1 a démontré une très forte adaptabilité dans plusieurs tâches d'alignement, de suivi d'instructions et d'utilisation d'outils. Ceci est dû à son architecture innovante héritée de HunYuan Turbo S, et à l'utilisation du mode de fusion Hybrid-Mamba-Transformer. Il s'agit de la première application industrielle sans perte de l'architecture hybride Mamba à un modèle d'inférence de très grande taille, réduisant efficacement la complexité de calcul de la structure Transformer traditionnelle, diminuant l'occupation de la mémoire du KV-Cache, et réduisant ainsi considérablement les coûts d'entraînement et d'inférence.
De plus, grâce à sa remarquable capacité de capture de longs textes, HunYuan T1 peut efficacement résoudre les problèmes de perte de contexte et de dépendance à l'information à longue distance, fréquents dans le raisonnement sur de longs textes. L'architecture hybride Mamba a été optimisée spécifiquement pour le traitement de longues séquences, permettant, grâce à un calcul efficace, de garantir la capacité de capture d'informations dans les longs textes tout en réduisant considérablement la consommation de ressources. Avec un nombre de paramètres d'activation similaire, HunYuan T1 a doublé sa vitesse de décodage.
Actuellement, Tencent HunYuan T1 est accessible et un service API est disponible. Les utilisateurs peuvent, selon leurs besoins, bénéficier de la commodité et de l'efficacité de ce puissant modèle d'inférence, à un prix de 1 yuan pour un million de tokens en entrée et de 4 yuans pour un million de tokens en sortie.