ExtractThinker
Intelligentes Dokumentenverarbeitungsframework, speziell für LLMs entwickelt
Normales ProduktProduktivitätDokumentenverarbeitungLLM-Integration
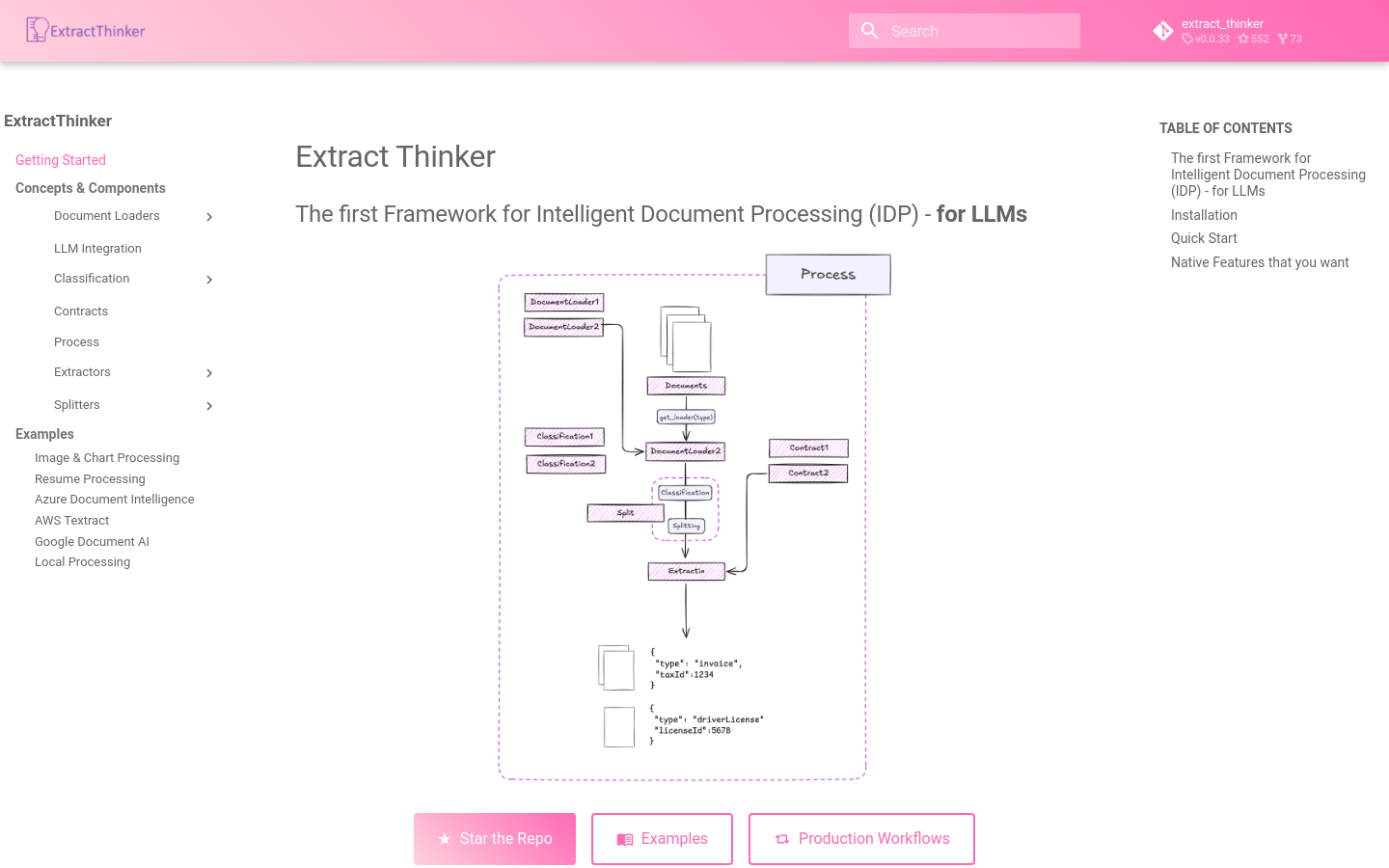
ExtractThinker ist ein flexibles Framework für die intelligente Dokumentenverarbeitung, das Benutzern hilft, strukturierte Daten aus verschiedenen Dokumenten zu extrahieren und zu klassifizieren – ähnlich einem ORM für Dokumentenverarbeitungs-Workflows. Es wird als „Dokumentenintelligenz für LLMs“ oder „LangChain für die intelligente Dokumentenverarbeitung“ bezeichnet. Die Motivation für dieses Framework besteht darin, die für die Dokumentenverarbeitung benötigten spezifischen Funktionen bereitzustellen, wie z. B. die Aufteilung großer Dokumente und die erweiterte Klassifizierung.
ExtractThinker Neueste Verkehrssituation
Monatliche Gesamtbesuche
Keine Daten verfügbar
Absprungrate
Keine Daten verfügbar
Durchschnittliche Seiten pro Besuch
Keine Daten verfügbar
Durchschnittliche Besuchsdauer
Keine Daten verfügbar
ExtractThinker Besuchstrend
Keine Besuchsdaten verfügbar
ExtractThinker Geografische Verteilung der Besuche
Keine geografischen Verteilungsdaten verfügbar
ExtractThinker Traffic-Quellen
Keine Traffic-Quellendaten verfügbar
