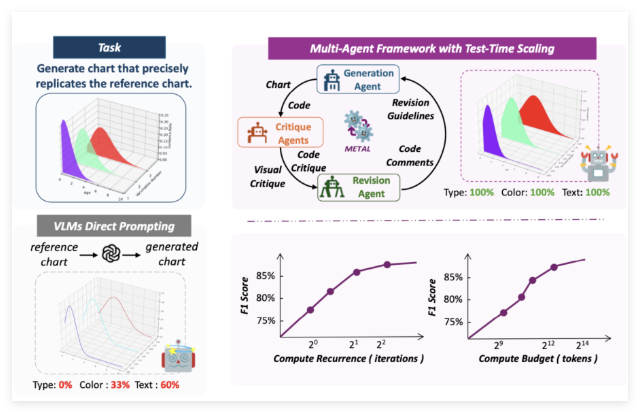
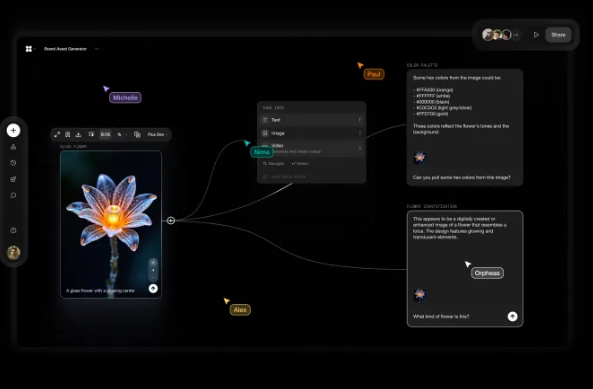
जनरेटिव एआई तेजी से विकसित हो रहा है, लेकिन इसके प्रदर्शन का समग्र मूल्यांकन करना हमेशा एक चुनौती रही है। विभिन्न मॉडल लगातार सामने आ रहे हैं, और उनके परिणाम भी दिन-ब-दिन आश्चर्यजनक होते जा रहे हैं। लेकिन सवाल यह है, इन टेक्स्ट-टू-इमेज मॉडलों के परिणामों का मूल्यांकन कैसे किया जाए?
परंपरागत मूल्यांकन विधियाँ या तो मानव आंख पर निर्भर करती हैं, जो कि बहुत ही व्यक्तिपरक होती हैं; या कुछ सरल मापदंडों का उपयोग करती हैं, जैसे CLIPScore, लेकिन ये मापदंड अक्सर जटिल टेक्स्ट संकेतों में विवरण को पकड़ने में असफल होते हैं, जैसे कि वस्तुओं के बीच के संबंध, तार्किक निष्कर्ष आदि। इससे कई टेक्स्ट-टू-इमेज मॉडलों के मूल्यांकन परिणाम गलत होते हैं, यहां तक कि कुछ मजेदार स्थितियाँ भी उत्पन्न होती हैं, जहां स्पष्ट रूप से उत्पन्न की गई छवि में कोई संबंध नहीं होता, फिर भी स्कोर काफी ऊँचा होता है।

इस समस्या को हल करने के लिए, कार्नेगी मेलॉन यूनिवर्सिटी और मेटा के शोधकर्ताओं ने हाल ही में एक नया टेक्स्ट-टू-इमेज मूल्यांकन योजना - VQAScore पेश किया है। इस योजना का मुख्य विचार यह है कि टेक्स्ट-टू-इमेज मॉडलों को स्कोर देने के लिए विजुअल क्वेश्चन आंसरिंग (VQA) मॉडल का उपयोग किया जाए।

विशेष रूप से, VQAScore पहले टेक्स्ट संकेत को एक सरल प्रश्न में बदलता है, जैसे "क्या इस चित्र में एक बिल्ली एक चूहा का पीछा कर रही है?" फिर उत्पन्न की गई छवि और इस प्रश्न को VQA मॉडल को दिया जाता है। VQA मॉडल चित्र की सामग्री के आधार पर प्रश्न का उत्तर "हां" या "नहीं" के रूप में निर्धारित करेगा, और VQAScore VQA मॉडल द्वारा "हां" की संभावना के आधार पर टेक्स्ट-टू-इमेज मॉडल को स्कोर देगा।

यह विधि सरल लगती है, लेकिन इसका प्रभाव आश्चर्यजनक रूप से अच्छा है। शोधकर्ताओं ने VQAScore का उपयोग करके 8 विभिन्न टेक्स्ट-टू-इमेज मूल्यांकन मानकों पर परीक्षण किया, और परिणाम पाया कि VQAScore की सटीकता और विश्वसनीयता पारंपरिक मूल्यांकन विधियों से कहीं अधिक है, और यह उन योजनाओं के साथ भी तुलना की जा सकती है जो GPT-4V जैसे बड़े मॉडलों का उपयोग करती हैं।
और भी बेहतर यह है कि VQAScore न केवल टेक्स्ट-टू-इमेज का मूल्यांकन करने के लिए उपयोग किया जा सकता है, बल्कि टेक्स्ट-टू-वीडियो और टेक्स्ट-टू-3D मॉडल का मूल्यांकन करने के लिए भी किया जा सकता है। इसका कारण यह है कि VQAScore का मूल VQA मॉडल है, और VQA मॉडल स्वयं विभिन्न प्रकार की दृश्य सामग्री को संभाल सकता है।

टेक्स्ट-टू-इमेज क्षेत्र में प्रगति को और बढ़ावा देने के लिए, शोधकर्ताओं ने एक नया टेक्स्ट-टू-इमेज मूल्यांकन मानक - GenAI-Bench भी बनाया है। इस मानक में 1600 जटिल टेक्स्ट संकेत शामिल हैं, जो विभिन्न दृश्य भाषा तर्क क्षमताओं को कवर करते हैं, जैसे तुलना, गिनती, तार्किक निष्कर्ष आदि। शोधकर्ताओं ने विभिन्न टेक्स्ट-टू-इमेज मॉडलों के प्रदर्शन का मूल्यांकन करने के लिए 15000 से अधिक मानव द्वारा लेबल किए गए डेटा भी एकत्र किए हैं।
कुल मिलाकर, VQAScore और GenAI-Bench की उपस्थिति ने टेक्स्ट-टू-इमेज क्षेत्र में नई ऊर्जा लाने का काम किया है। VQAScore एक अधिक सटीक और विश्वसनीय मूल्यांकन विधि प्रदान करता है, जो शोधकर्ताओं को विभिन्न मॉडलों के लाभ और हानि का बेहतर मूल्यांकन करने में मदद कर सकता है। GenAI-Bench एक अधिक व्यापक और चुनौतीपूर्ण मूल्यांकन मानक प्रदान करता है, जो टेक्स्ट-टू-इमेज मॉडलों को अधिक बुद्धिमान और मानव-केंद्रित दिशा में विकसित करने में मदद करता है।
बेशक, VQAScore की कुछ सीमाएँ भी हैं। वर्तमान में, VQAScore मुख्य रूप से ओपन-सोर्स VQA मॉडलों पर निर्भर करता है, और इन मॉडलों का प्रदर्शन GPT-4V जैसे क्लोज़-सोर्स मॉडलों की तुलना में कम है। भविष्य में, जैसे-जैसे VQA मॉडल में निरंतर प्रगति होगी, VQAScore का प्रदर्शन भी और बेहतर होगा।
परियोजना का पता: https://linzhiqiu.github.io/papers/vqascore/