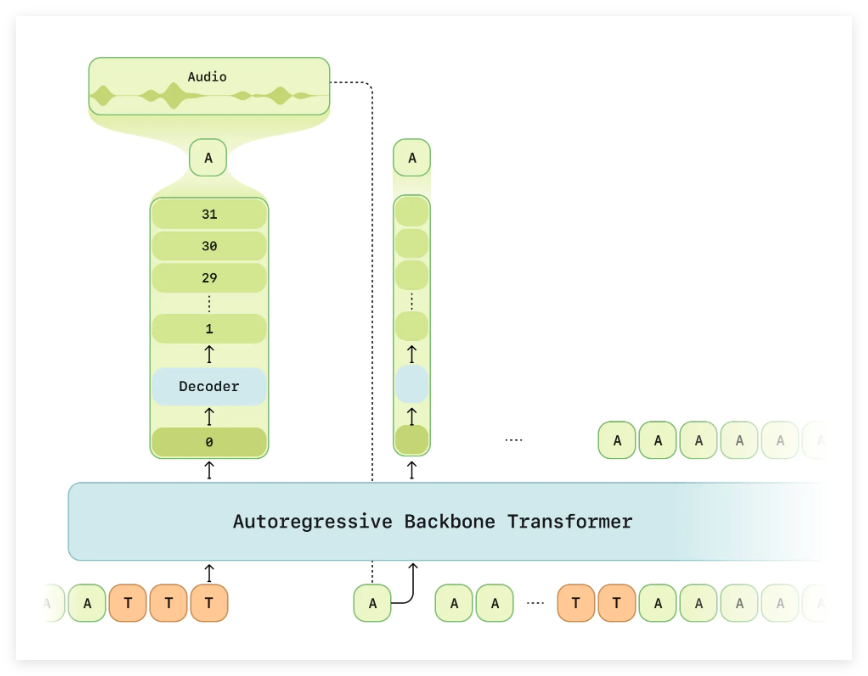
13 मार्च को, सेसम कंपनी ने अपने नवीनतम वॉयस सिंथेसिस मॉडल CSM को लॉन्च किया, जिसने उद्योग में ध्यान आकर्षित किया। आधिकारिक जानकारी के अनुसार, CSM एक एंड-टू-एंड ट्रांसफॉर्मर-आधारित मल्टीमॉडल लर्निंग आर्किटेक्चर का उपयोग करता है, जो संदर्भ जानकारी को समझ सकता है और प्राकृतिक और भावनात्मक रूप से समृद्ध आवाज उत्पन्न कर सकता है, जिसकी आवाज असली इंसान की तरह लगती है, जो आश्चर्यजनक है।
यह मॉडल रीयल-टाइम वॉयस जनरेशन का समर्थन करता है, टेक्स्ट और ऑडियो इनपुट को संभाल सकता है, और उपयोगकर्ता स्वर, स्वर, ताल और भावनाओं जैसी विशेषताओं को नियंत्रित करने के लिए पैरामीटर को समायोजित कर सकते हैं, उच्च स्तर की लचीलापन प्रदर्शित करते हैं।
CSM को AI वॉयस टेक्नोलॉजी में एक महत्वपूर्ण सफलता माना जाता है। इसकी वॉयस प्राकृतिकता बहुत अधिक है, यहाँ तक कि "यह पहचानना असंभव है कि यह कृत्रिम रूप से संश्लेषित है या असली इंसान की आवाज है"। कुछ उपयोगकर्ताओं ने CSM के लगभग बिना देरी के प्रदर्शन को दिखाते हुए वीडियो रिकॉर्ड किए हैं, इसे "अनुभव किया गया सबसे शक्तिशाली मॉडल" कहा है। इससे पहले, सेसम ने CSM-1B का एक छोटा संस्करण ओपन सोर्स किया था, जो बहु-चरण संवादों में सुसंगत आवाज उत्पन्न करने का समर्थन करता है, और व्यापक प्रशंसा प्राप्त की थी।
वर्तमान में, CSM मुख्य रूप से अंग्रेजी प्रशिक्षण के लिए है, और उत्कृष्ट प्रदर्शन करता है, लेकिन बहु-भाषा समर्थन में अभी भी सीमाएँ हैं। वर्तमान में यह चीनी भाषा का समर्थन नहीं करता है, लेकिन भविष्य में विस्तार की उम्मीद है।
सेसम ने कहा कि वह कुछ शोध परिणामों को ओपन सोर्स करेगा, और समुदाय के डेवलपर्स पहले ही GitHub पर इसकी क्षमता पर चर्चा कर रहे हैं। CSM न केवल संवादात्मक AI के लिए उपयुक्त है, बल्कि शिक्षा, मनोरंजन आदि क्षेत्रों में वॉयस इंटरैक्शन अनुभव में क्रांति ला सकता है। उद्योग के विशेषज्ञों का मानना है कि CSM AI वॉयस असिस्टेंट के मानकों को फिर से परिभाषित कर सकता है और अधिक प्राकृतिक मानव-मशीन संवाद ला सकता है।