
ぼやけた写真に悩んでいませんか?画期的な画像超解像度ツール「InvSR」が登場!シンプルな手順で、画像を瞬時に鮮明にします。このツールの強みは、大規模な事前学習済み拡散モデルが持つ豊富な画像情報を活用し、効率的で高品質な画像解像度向上を実現している点です。

ぼやけた写真に悩んでいませんか?画期的な画像超解像度ツール「InvSR」が登場!シンプルな手順で、画像を瞬時に鮮明にします。このツールの強みは、大規模な事前学習済み拡散モデルが持つ豊富な画像情報を活用し、効率的で高品質な画像解像度向上を実現している点です。

先日、開発者scraedがGitHub上でLanPaintを公開しました。これは、追加のトレーニングなしで画像修復を行うツールです。このツールは、ユーザーが独自のモデルを含むあらゆる安定拡散モデル(SD)で高品質の画像修復を実現することを目的としています。LanPaintは、ノイズ除去の前にモデルに「思考」させることで、よりシームレスで正確な修復結果を得ます。LanPaintの主な特徴の一つは、ゼロトレーニング修復です。ユーザーはすぐに…
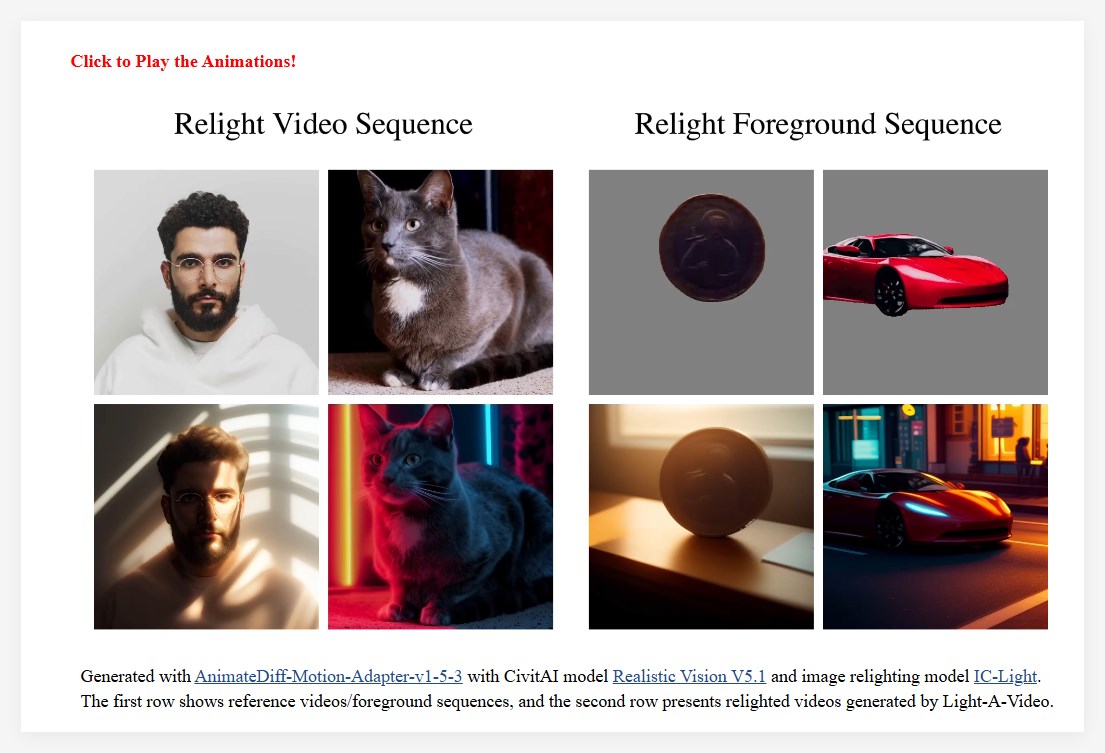
近年、大規模データセットと事前学習済み拡散モデルのおかげで画像再照明技術は進歩し、一貫性のある照明の適用がより一般的になりました。しかし、ビデオ再照明の分野では、高額なトレーニングコストと多様で高品質なビデオ再照明データセットの不足により、進歩は比較的遅れています。画像再照明モデルをビデオにフレームごとに適用するだけでは、光源の一貫性のなさや再照明された外観の一貫性のなさが原因で、最終的に生成されたビデオにちらつきが生じるなど、様々な問題が発生します。この問題を解決するために、研究チームはLight-Aを提案しました。

ニューヨーク大学、マサチューセッツ工科大学、Googleの研究チームは最近、拡散モデルにおける推論時間のスケーリングにおけるボトルネック問題に対処することを目的とした革新的なフレームワークを発表しました。この画期的な研究は、従来の単純なノイズ除去ステップの増加という方法を超え、生成モデルの性能向上のための新たな道を切り開きます。このフレームワークは主に2つの次元から展開されます。1つは検証器からのフィードバックを利用すること、もう1つはより最適なノイズ候補を発見するためのアルゴリズムを実装することです。研究チームは、256×256解像度の事前学習済みSiT-XLモデルをベースに、250回の固定ノイズ除去ステップを維持しながら…

ゲーム開発において、シーンの多様性と創造性は長年の課題でした。最近、香港大学と快手科技は共同で、GameFactoryという革新的なフレームワークを開発しました。これはゲーム動画生成におけるシーン汎化問題を解決することを目指しています。このフレームワークは、事前学習済みのビデオ拡散モデルを利用し、オープンワールドの動画データでトレーニングすることで、新しく多様なゲームシーンを生成できます。ビデオ拡散モデルは、高度な生成技術として近年、動画生成や物理シミュレーション分野で大きな可能性を示しています。