पेगासस-1
एक शक्तिशाली वीडियो-पाठ निर्माण मॉडल
सामान्य उत्पादवीडियोवीडियोपाठ निर्माण
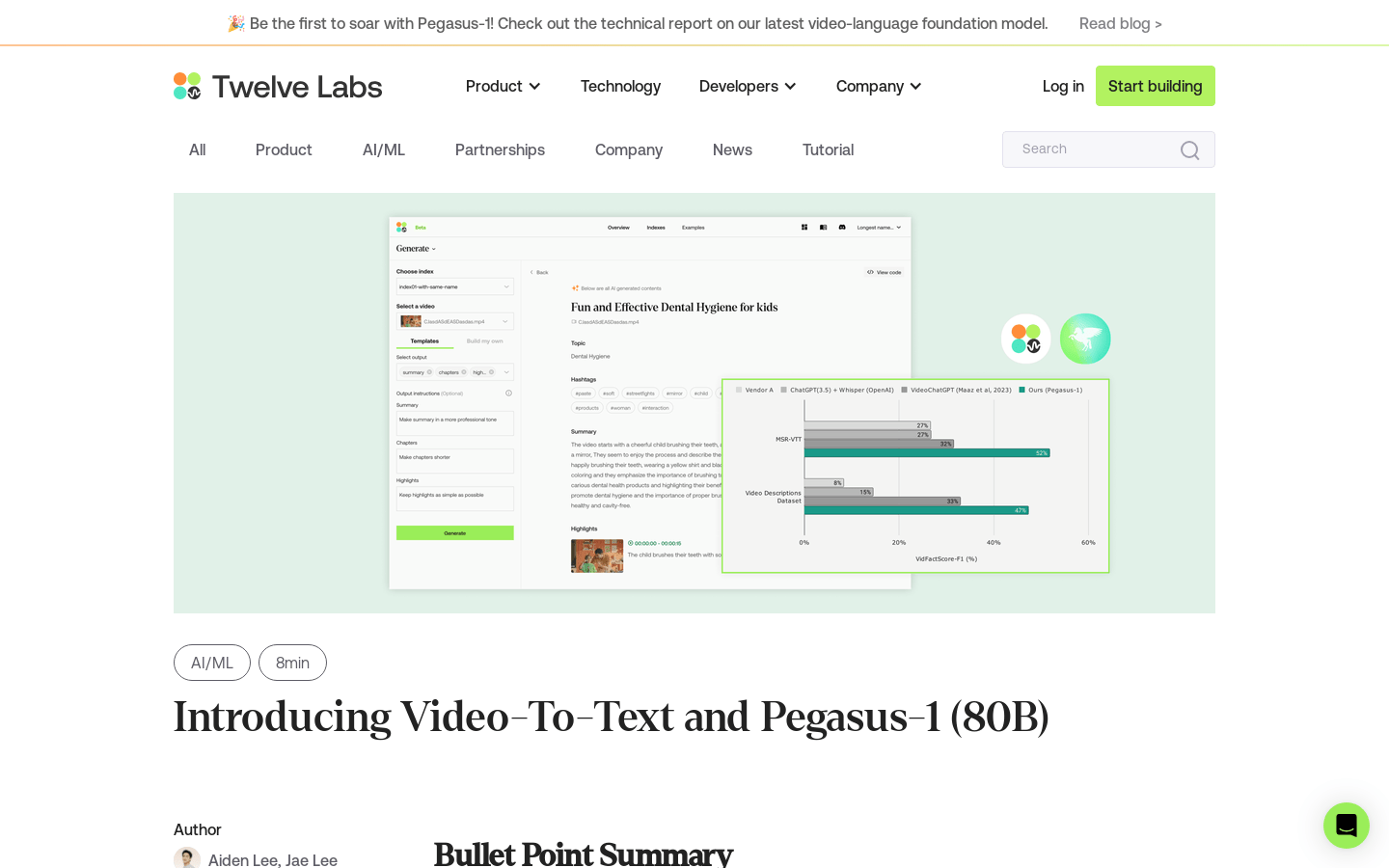
ट्वेल्व लैब्स द्वारा विकसित पेगासस-1 एक शक्तिशाली वीडियो-पाठ निर्माण मॉडल है जो वीडियो के शीर्षक, सारांश और कस्टम पाठ आउटपुट उत्पन्न करने में सक्षम है। इस मॉडल में ८०B पैरामीटर हैं, और यह अपने पूर्ववर्ती वीडियो-भाषा मॉडलों की तुलना में MSR-VTT डेटासेट पर ६१% और वीडियो विवरण डेटासेट पर ४७% बेहतर प्रदर्शन करता है। उपयोगकर्ता API कॉल के माध्यम से पेगासस-1 मॉडल का उपयोग करके वीडियो के पाठ आउटपुट, जैसे शीर्षक, सारांश, अध्याय और कस्टम प्रारूप उत्पन्न कर सकते हैं। पेगासस-1 मॉडल वीडियो की दृश्य, श्रव्य और ध्वनि जानकारी पर पूरा ध्यान देता है, और मौजूदा समाधानों की तुलना में यह अधिक व्यापक और सटीक पाठ उत्पन्न करता है।
पेगासस-1 नवीनतम ट्रैफ़िक स्थिति
मासिक कुल विज़िट
अभी तक कोई डेटा नहीं
बाउंस दर
अभी तक कोई डेटा नहीं
प्रति विज़िट औसत पृष्ठ
अभी तक कोई डेटा नहीं
औसत विज़िट अवधि
अभी तक कोई डेटा नहीं
पेगासस-1 विज़िट प्रवृत्ति
अभी तक कोई विज़िट डेटा नहीं
पेगासस-1 विज़िट भौगोलिक वितरण
अभी तक कोई भौगोलिक वितरण डेटा नहीं
पेगासस-1 ट्रैफ़िक स्रोत
अभी तक कोई ट्रैफ़िक स्रोत डेटा नहीं