Recently, the research team at Nous Research brought exciting news to the tech community with the introduction of a new optimizer called DisTrO (Distributed Internet Training). The birth of this technology signifies that powerful AI models are no longer exclusive to large companies; ordinary individuals now have the opportunity to train them efficiently on their personal computers at home.
The magic of DisTrO lies in its ability to significantly reduce the amount of information that needs to be transferred between multiple graphics processing units (GPUs) during AI model training. This innovation allows powerful AI models to be trained under ordinary network conditions, enabling collaboration among individuals or institutions worldwide to jointly develop AI technologies.

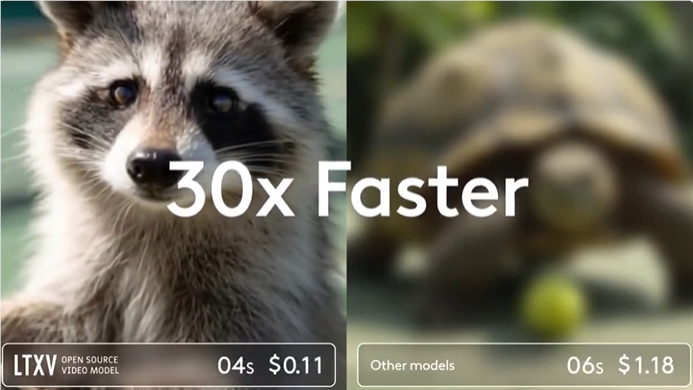
According to Nous Research's technical paper, the efficiency of DisTrO is astonishing. Training efficiency using DisTrO is 857 times higher than a common algorithm—All-Reduce—while the amount of information required to be transferred in each training step has been reduced from 74.4GB to 86.8MB. This improvement not only makes training faster and more affordable but also means more people have the opportunity to participate in this field.
Nous Research stated on their social media platform that with DisTrO, researchers and institutions no longer need to rely on a single company to manage and control the training process, providing them with more freedom to innovate and experiment. This open competitive environment helps drive technological progress, ultimately benefiting society as a whole.
The demand for hardware in AI training often deters many. Especially high-performance Nvidia GPUs have become increasingly scarce and expensive, with only well-funded companies able to afford such training burdens. However, Nous Research's philosophy is completely opposite; they are committed to opening up AI model training to the public at a lower cost, striving to enable more people to participate.
The working principle of DisTrO is to reduce the need for full gradient synchronization between GPUs, thereby reducing communication overhead by four to five orders of magnitude. This innovation allows AI models to be trained over slower internet connections, with many households now easily able to access speeds of 100Mbps download and 10Mbps upload.
In preliminary tests on Meta's Llama2 large language model, DisTrO showed training effects comparable to traditional methods while significantly reducing the required communication volume. Researchers also stated that although tests have been conducted on smaller models so far, they initially speculate that as model sizes increase, the reduction in communication needs could be even more significant, possibly reaching 1000 to 3000 times.
It is worth noting that while DisTrO makes training more flexible, it still relies on GPU support, albeit now these GPUs do not need to be located in the same place but can be dispersed worldwide and collaborate via ordinary internet. We have seen that DisTrO, when rigorously tested with 32 H100 GPUs, matches the convergence speed of the traditional AdamW+All-Reduce method but dramatically reduces communication needs.
DisTrO is not only suitable for large language models but also has the potential to be used for training other types of AI, such as image generation models, with future applications looking promising. Additionally, by enhancing training efficiency, DisTrO could reduce the environmental impact of AI training by optimizing the use of existing infrastructure and reducing the need for large data centers.
Through DisTrO, Nous Research is not only advancing the technological progress of AI training but also fostering a more open and flexible research ecosystem, opening up infinite possibilities for future AI development.
Reference: https://venturebeat.com/ai/this-could-change-everything-nous-research-unveils-new-tool-to-train-powerful-ai-models-with-10000x-efficiency/