Kunlun Wanwei's Self-Developed Large Model Surpasses GPT-3.5 and LLaMA2 in Inference Capability
站长之家
57
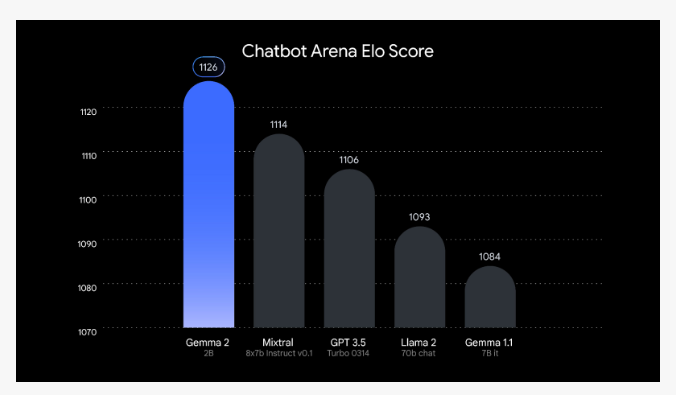
Kunlun Tech has announced that its self-developed TianGong large model achieved an accuracy rate of 80% on the Benchmark GSM8K test, surpassing both GPT-3.5 and LLaMA2-70B, reaching a global leading level, close to that of GPT-4. The TianGong large model also performed exceptionally well on multiple datasets including MMLU, C-EVAL, and HumanEval, with accuracy rates higher than those of other mainstream large models. The reasoning capability of the TianGong large model exceeds that of GPT-3.5 and LLaMA2-70B, and compared to GPT-3.5, the problem-solving approach of the TianGong large model is simpler and clearer. Currently in the internal testing phase, the TianGong large model will continue to enhance its technical prowess, providing robust intelligent support for users and businesses.
This article is from AIbase Daily
Welcome to the [AI Daily] column! This is your daily guide to exploring the world of artificial intelligence. Every day, we present you with hot topics in the AI field, focusing on developers, helping you understand technical trends, and learning about innovative AI product applications.
—— Created by the AIbase Daily Team
© Copyright AIbase Base 2024, Click to View Source -