In the field of academic research, literature retrieval is a complex and crucial information-gathering task. Researchers need to be able to handle sophisticated search capabilities within specialized knowledge domains to meet detailed research demands. However, existing academic search platforms, such as Google Scholar, often struggle to address these complex research queries. For instance, a specialized query on non-stationary reinforcement learning using the UCB method requires stronger computational and analytical abilities. Additionally, researchers typically spend a significant amount of time and effort manually browsing vast academic databases when conducting literature reviews.

Although several studies have explored the application of large language models (LLMs) in academic paper retrieval and scientific discovery, traditional search tools still struggle to meet the complex needs of specialized research. Many studies focus on developing LLM agents through optimization frameworks and prompt engineering techniques. While methods like the AGILE RL framework have significantly enhanced the comprehensive capabilities of these agents, a fully autonomous and precise academic paper retrieval solution has yet to be found, leaving a substantial gap in research.
Recently, researchers from ByteDance Research Institute and Peking University jointly proposed PaSa, an innovative LLM-based paper search agent. PaSa can autonomously execute complex search strategies, including tool invocation, paper reading, and reference selection, aiming to generate comprehensive and accurate results for complex academic queries. To optimize PaSa's performance, the research team created AutoScholarQuery, a synthetic dataset containing 35,000 fine-grained academic queries, and established RealScholarQuery as a benchmark to evaluate the agent's actual performance. The system utilizes reinforcement learning techniques to enhance search capabilities, addressing the major limitations of existing academic search methods.
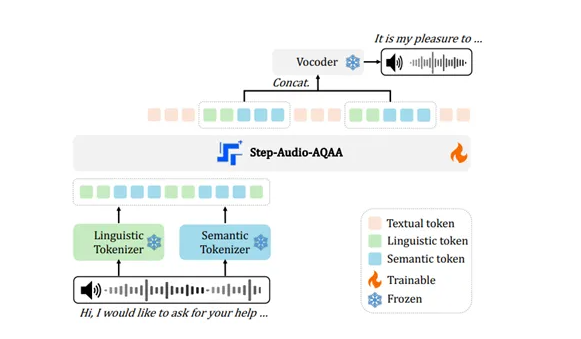
The PaSa system consists of two LLM agents: the Crawler and the Selector, which work together to perform comprehensive academic paper searches. The Crawler first analyzes the user's query to generate multiple refined search queries to retrieve relevant papers and adds these papers to a dedicated paper queue. The Crawler processes each queued paper, identifies and explores key citations that may expand the research scope, and dynamically adds newly discovered relevant papers to the list. Then, the Selector evaluates whether each paper meets the original query requirements.
Experimental results show that PaSa-7b outperforms existing search methods across multiple benchmarks. On the AutoScholarQuery test set, PaSa-7b achieved a 9.64% improvement in recall compared to PaSa-GPT-4o. When facing Google-based benchmarks, the recall improvement for PaSa-7b ranged from 33.80% to 42.64%. In the more challenging RealScholarQuery scenarios, PaSa-7b demonstrated a 30.36% increase in recall and a 4.25% increase in precision.
Overall, the launch of PaSa marks a significant advancement in academic paper search technology, providing an effective solution for information retrieval in academic research. By combining large language models and reinforcement learning techniques, PaSa greatly reduces the time and effort researchers spend on literature reviews while also providing them with an efficient tool to navigate the increasingly vast and complex academic literature landscape.
Code: https://github.com/bytedance/pasa
Paper: https://arxiv.org/abs/2501.10120
Key Points:
📄 **PaSa is an intelligent academic paper search agent jointly launched by ByteDance and researchers from Peking University.**
🤖 **The system consists of two LLM agents, the Crawler and the Selector, capable of autonomously executing complex search strategies.**
🏆 **Experimental results indicate that PaSa-7b outperforms existing search methods across multiple benchmarks, significantly enhancing the efficiency and accuracy of paper retrieval.**