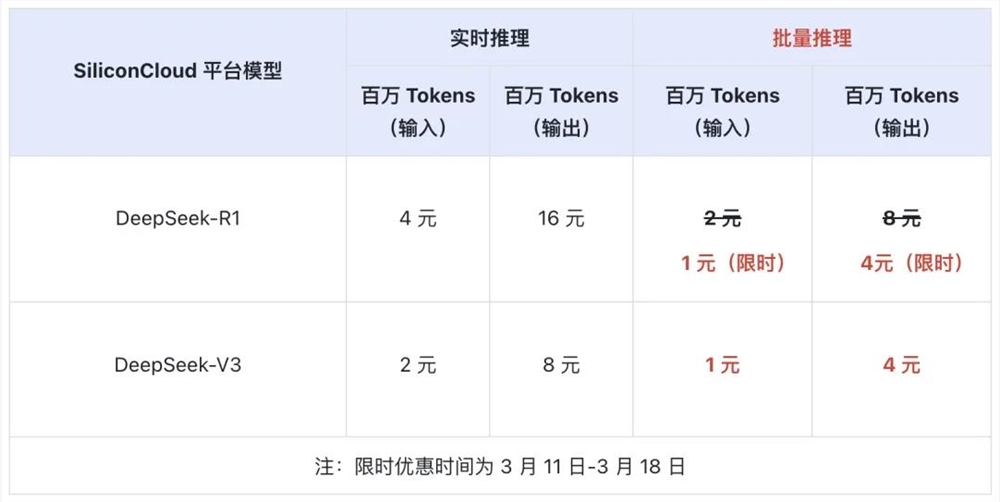
SiliconCloud's official WeChat account announces that batch inference is now supported for DeepSeek-R1 & V3 APIs on the SiliconCloud platform.
Users can send requests to SiliconCloud via the batch API, eliminating the constraints of real-time inference rates. Tasks are expected to be completed within 24 hours. Compared to real-time inference, the price of DeepSeek-V3 batch inference is reduced by 50%. From March 11th to March 18th, the price of DeepSeek-R1 batch inference is reduced by 75%, with an input price of ¥1/million Tokens and an output price of ¥4/million Tokens.
Batch inference helps users process large-scale data processing tasks more efficiently, such as generating reports and data cleaning, at a lower cost. It's ideal for data analysis and model performance evaluation scenarios where real-time responses aren't required.