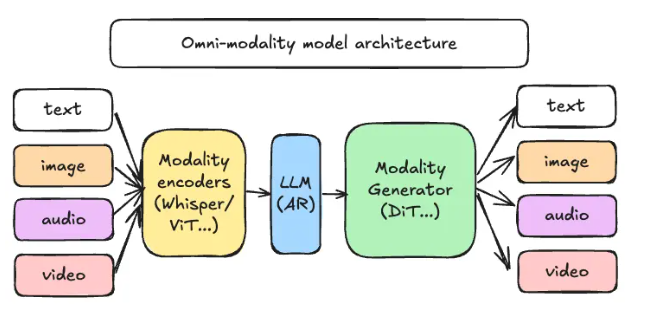
Recently, the open-source music generation model YuE, jointly developed by the Hong Kong University of Science and Technology and the music technology company DeepSeek, was officially released, stunning many music fans and creators. This model not only generates music in various styles but also simulates human vocals, offering listeners a completely new musical experience.
YuE's key feature is its dual LLaMA language model architecture, allowing seamless adaptation to various large language models and handling complete songs up to 5 minutes long. This innovative design elevates YuE's music generation quality to unprecedented heights, rivaling renowned closed-source music generation tools like Suno and Udio. YuE can simultaneously generate professional-grade vocals and accompaniment, achieving end-to-end music creation.

The research team incorporated a "dual-track next-token prediction" strategy into YuE, modeling vocal and accompaniment tracks separately to ensure musical detail and consistency. This approach not only improves sound quality but also significantly reduces information loss during content reconstruction. Furthermore, YuE's "structured progressive generation" technology allows the verse and chorus sections of a song to alternate within the same context, further enhancing the song's coherence.
To avoid plagiarism, YuE employs unique music context learning technology, enabling the model to learn from existing music snippets without repetition. This innovation not only enhances the model's musicality but also strengthens the originality of its creations. Ultimately, YuE demonstrated exceptional performance in multiple evaluations, earning positive user reviews.
With the release of YuE, the future of music creation is brimming with possibilities. Whether you're a professional musician or an amateur enthusiast, you can experience the joy of AI-powered music creation on this platform.
Project Address: https://github.com/multimodal-art-projection/YuE