苹果研究人员近日提出了俄罗斯套娃式扩散模型MDM,可以端到端生成1024x1024分辨率的高质量图像。MDM的创新在于引入了多分辨率扩散过程,通过嵌套UNet架构实现了多分辨率损失,大大提高了高分辨率输入去噪的收敛速度。另外,MDM还使用了渐进式训练,从低分辨率开始训练,逐步添加高分辨率输入和输出,极大地提高了训练效率。尽管训练数据集较小,但MDM展现出了生成高质量高分辨率图像和视频的强大能力。相比其他级联或潜在方法,MDM训练和推理更简单高效。
相关AI新闻推荐

字节Seedream 3.0 文生图模型技术报告发布:多项性能大幅升级
字节跳动Seed团队正式发布了Seedream3.0文生图模型的技术报告。这一模型在性能上实现了重大提升,是一个原生高分辨率、支持中英双语的图像生成基础模型,在分辨率、生图结构准确性等多方面取得突破,与上一版本相比优势显著。Seedream3.0在不同维度上的表现。本图各维度数据以最佳指标为参照系,已进行归一化调整。在功能亮点上,Seedream3.0可原生2K直出,无需后处理就能输出高分辨率图像,满足多种场景需求;出图速度极快,仅需3秒,极大提升创作效率;小字生成和文本排版效果得到优
2025年4月16号 14:27
6.8k

报道称OpenAI或将推出类X社交媒体功能,计划整合ChatGPT
人工智能领域的领军企业OpenAI正计划进一步扩展其业务版图。据多家媒体最新报道,OpenAI正在开发一项类似X(原Twitter)的社交媒体功能,并有可能将其整合进旗下广受欢迎的AI聊天工具ChatGPT中。项目处于早期阶段,聚焦图像生成与社交互动根据外媒The Verge报道,OpenAI目前已开发出该社交媒体功能的内部原型,核心功能围绕ChatGPT的图像生成能力展开。用户将能够通过ChatGPT生成AI图像,例如近期流行的动漫风格图像,并直接分享至社交信息流中,形成类似X平台的动态交流体验。这一功能的推
2025年4月16号 9:49
1.5k

OpenAI进军社交网络:融合图像生成与动态信息流 挑战X与Meta
人工智能巨头OpenAI正在悄然布局一项雄心勃勃的新计划——开发一款类似X的社交网络平台,这一项目目前处于早期开发阶段,内部原型已初具雏形,聚焦于ChatGPT的图像生成功能,并融入社交动态信息流。项目背景:从ChatGPT到社交生态OpenAI以ChatGPT的全球成功奠定了其在生成式AI领域的领先地位。据报道,ChatGPT已成为全球下载量最大的应用之一,覆盖约10%的全球人口。然而,面对Meta、Google及xAI等竞争对手在社交数据与用户粘性上的优势,OpenAI亟需新的增长点。社交网络的开发被认为是其战
2025年4月16号 9:37
2.2k

社交新宠!Ghiblio.art一键实现吉卜力风格转换
Ghiblio.art是一个专注于将照片转化为吉卜力风格艺术作品的在线AI工具。吉卜力工作室(Studio Ghibli)以其手绘风格、柔和色调和充满奇幻氛围的场景闻名,如《千与千寻》《龙猫》等经典作品。Ghiblio.art通过先进的AI算法,自动将用户上传的照片重塑为吉卜力风格的插画,赋予普通图像梦幻的动画质感。AIbase了解到,用户只需上传照片,选择吉卜力风格滤镜,平台即可在数秒内生成高质量的艺术图像。社交媒体上,用户对Ghiblio.art的操作简便性和生成效果赞不绝口,称其“仿佛将现实带入了
2025年4月16号 9:36
2.8k

ChatGPT重磅更新:新增图像库功能,可查看自己用GPT生成的所有图片
OpenAI宣布ChatGPT迎来一项重大更新:全新 图像库功能正式上线,允许用户在统一的界面中查看、编辑和分享通过GPT-4o模型生成的所有图片。这一功能现已向免费、Plus及Pro用户逐步开放,显著提升了用户在AI图像生成领域的创作体验。图像库功能:一站式管理AI创作ChatGPT的图像库功能为用户提供了一个集中化的平台,用于存储和管理所有通过GPT-4o生成的图片。无论是基于文本提示生成的艺术作品,还是从用户上传的图像转换的风格化内容(如Studio Ghibli风格或卡通效果),所有创作都将自动归档
2025年4月16号 9:35
3.7k
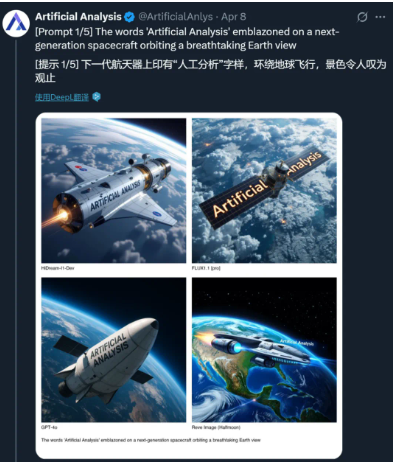
国内首款开源AI图像生成模型HiDream-I1发布,实力堪比GPT-4o
最近,AI 领域迎来了重磅消息:拥有17亿参数的开源图像生成模型 HiDream-I1正式发布。此款模型不仅在生成图像的质量上表现出色,甚至在某些方面超越了目前备受瞩目的 GPT-4o。HiDream-I1的发布使得普通用户在无需订阅的情况下,也能体验到先进的图像生成和编辑技术。HiDream-I1由国内公司智象未来研发,成功跻身人工智能基准测试平台 Artificial Analysis 的竞争榜单,迅速成为开源模型的新标杆。这一模型在上线后的24小时内便登顶,成为第一个占据该平台榜首的中国自研生成式 AI 模型。通过与
2025年4月15号 13:50
7.5k

字节跳动开源项目UNO:图片生成可以保持角色、物体一致性
人工智能(AI)在图像生成领域取得了显著的进展,但如何让AI在生成不同场景或进行多次创作时,保持图像中特定角色或物体的一致性,一直是行业内的重要挑战。近日,字节跳动旗下的智能创作团队发布了其最新的开源项目 UNO,旨在通过创新技术,解锁更强的生成可控性,尤其是在保持图像主体一致性方面,为AI图像生成领域带来了新的突破。AI作图“脸盲症”?UNO帮你记住“主角”在以往的AI图像生成过程中,即使输入相同的描述,每次生成的人物、物品也可能在外观上存在显著差异,
2025年4月14号 9:35
4.3k

图像生成框架VisualCloze发布:通过视觉上下文学习实现高度灵活的图像生成
人工智能在图像生成领域的创新步伐从未停歇。近日,Hugging Face平台上线了一款名为VisualCloze的全新工具,以其独特的视觉上下文学习(Visual In-Context Learning)技术,标志着通用图像生成框架的又一重大突破。AIbase通过整理社交媒体上的最新动态,深入剖析这一工具的亮点与潜力,为读者带来第一手报道。VisualCloze亮相:通用图像生成的全新范式VisualCloze作为Hugging Face的最新开源项目,旨在通过视觉上下文学习实现高度灵活的图像生成。不同于传统的图像生成模型,VisualCloze能够基于少量示例
2025年4月11号 17:44
9.2k

华为诺亚方舟实验室携手港大发布最强开源扩散语言模型 Dream 7B,打破文本生成格局
人工智能领域再添一颗耀眼新星!近日,华为诺亚方舟实验室与香港大学自然语言处理组(HKU NLP Group) 联合发布了名为 Dream7B 的全新语言模型。这款模型被誉为“迄今为止最强大的开源扩散大型语言模型”。Dream7B 的问世,不仅在性能上超越了现有的扩散语言模型,更在通用能力、数学、代码以及规划能力上,比肩甚至超越了同等规模的顶尖自回归(AR)语言模型。这一突破性的进展,预示着文本生成领域或将迎来新的技术范式。颠覆传统:扩散模型赋能更强语言理解与生成长期以来,以 GP
2025年4月11号 10:07
8.6k

Canva发布全新AI功能:涵盖AI助手、指令生成应用、动态表格等
在线设计平台Canva于近日宣布,将为其平台引入一系列创新AI功能,涵盖AI助手、指令生成应用、电子表格支持以及AI驱动的编辑工具等多个方面。这些新功能旨在进一步简化设计流程,提升用户创意表达的效率与多样性。Canva AI助手:智能化的创意伙伴Canva此次推出的核心功能之一是Canva AI助手,一款基于对话的AI工具,集成了图像生成、文本创作和设计编辑等多种能力。用户可以通过文本或语音指令,与AI助手互动,快速生成从社交媒体素材到演示文稿的多样化内容。AI助手还能根据用户需求
2025年4月11号 9:22
2.4k