en
AI Ranking
每月不到10元,就可以无限制地访问最好的AIbase。立即成为会员
Home
News
Daily Brief
Income Guide
Tutorial
Tools Directory
Product Library
en
AI Ranking
Search AI Products and News
Explore worldwide AI information, discover new AI opportunities
AI News
AI Tools
AI Cases
AI Tutorial
Type :
AI News
AI Tools
AI Cases
AI Tutorial
2024-09-26 16:28:02
.
AIbase
.
12.0k
Easily Identify Audio Forgery! Zhejiang University and Tsinghua University Join Forces to Create the AI Voice Privacy Protection Tool SafeEar
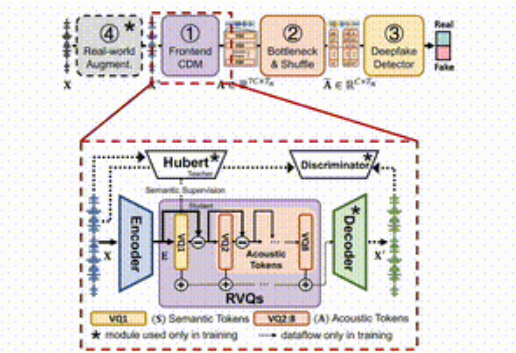
In today's rapidly advancing world of artificial intelligence, voice synthesis and transformation technologies are evolving at an extraordinary pace, providing us with incredibly realistic and natural audio experiences. However, these technological advancements also bring potential security risks, particularly as 'voice cloning' technology could be exploited by malicious individuals, threatening personal privacy and social stability. In response to this challenge, the Intelligent System Security Laboratory of Zhejiang University and Tsinghua University have joined forces to launch a revolutionary audio forgery detection framework - SafeEar. This framework not only efficiently detects forged audio but also ensures privacy protection during the detection process.
2024-09-26 16:23:47
.
AIbase
.
12.0k
Jointly Developed by Zhejiang University and Tsinghua University! Voice Forgery Detection Framework SafeEar Achieves an Error Rate as Low as 2.02%
In the context of rapid advancements in voice synthesis technology, voice forgery has become increasingly severe, posing significant threats to user privacy and social security. Recently, the Intelligent System Security Laboratory at Zhejiang University and Tsinghua University jointly released a novel voice forgery detection framework called 'SafeEar.' This framework aims to efficiently detect forgeries while protecting the privacy of voice content. The concept behind SafeEar is to cleverly design a decoupled model based on neural audio codecs that effectively separates the acoustic features of voice.