2024-12-16 14:41:42.AIbase.14.0k
Nexa AI Launches OmniAudio-2.6B: A Fast Audio Language Model for Edge Deployment
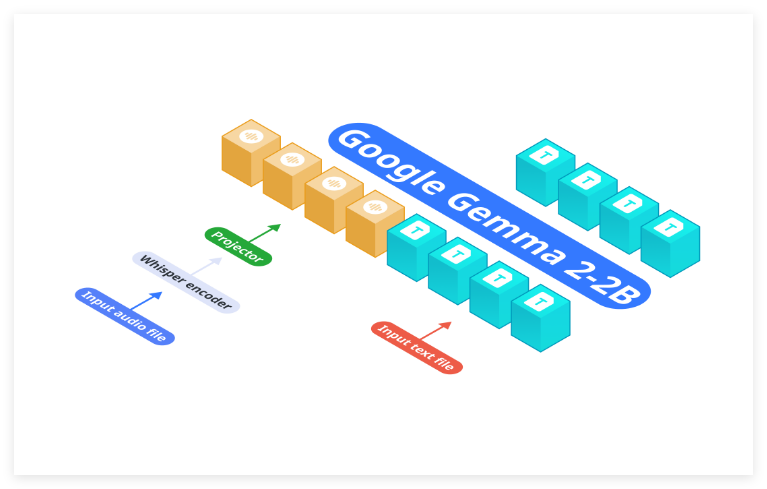
Nexa AI recently unveiled its new OmniAudio-2.6B audio language model, designed to meet the efficient deployment demands of edge devices. Unlike traditional architectures that separate automatic speech recognition (ASR) and language models, OmniAudio-2.6B integrates Gemma-2-2b, Whisper Turbo, and a custom projector into a unified framework. This design eliminates the inefficiencies and delays associated with linking various components in traditional systems, making it especially suitable for resource-constrained computing.