ExtractThinker
Framework de traitement intelligent de documents, spécialement conçu pour les LLMs
Produit OrdinaireProductivitéTraitement de documentsIntégration LLM
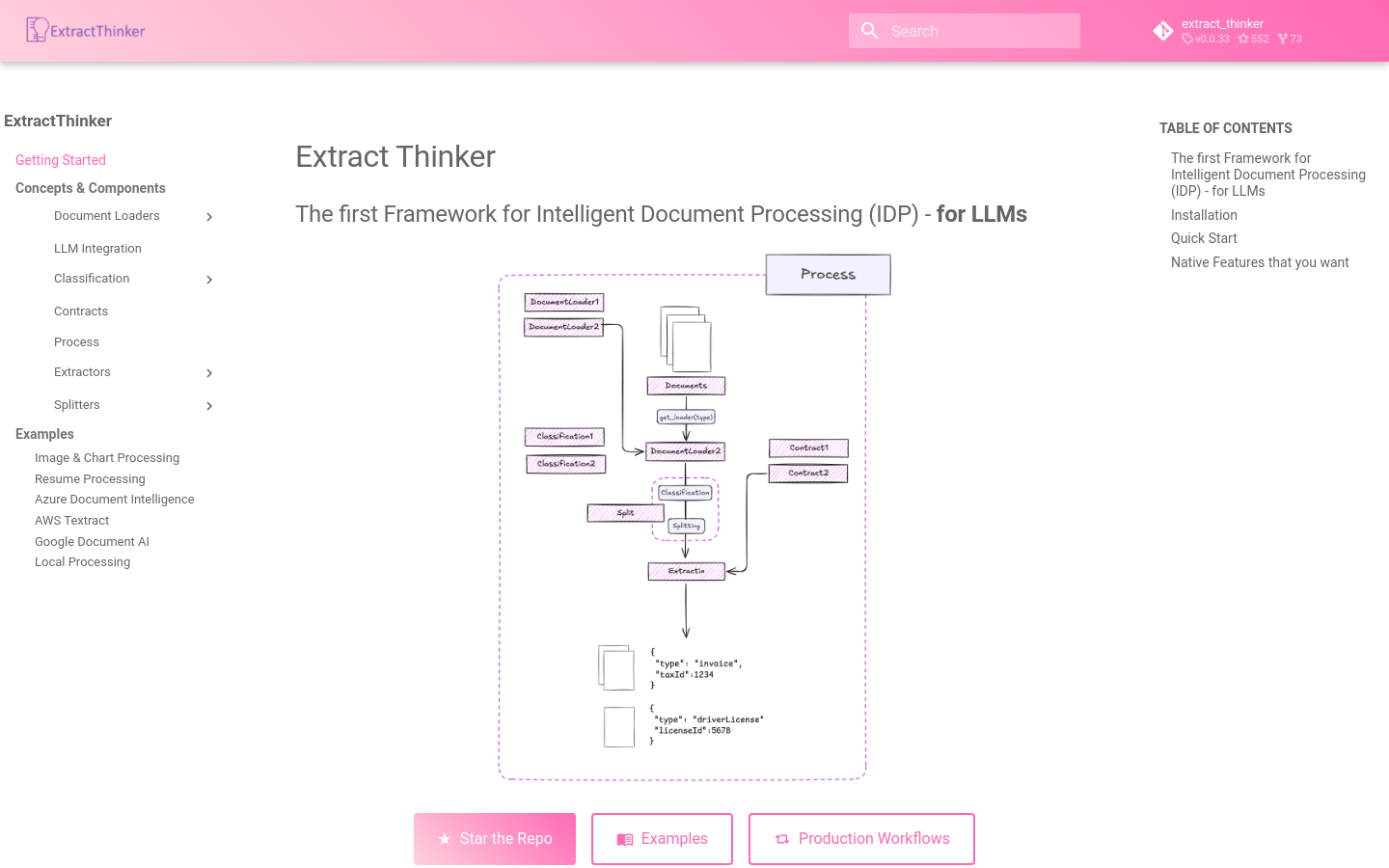
ExtractThinker est un framework flexible et intelligent pour le traitement de documents, aidant les utilisateurs à extraire et à classer des données structurées à partir de divers documents. Il fonctionne comme un ORM pour les flux de travail de traitement de documents. Il est décrit comme « l'intelligence documentaire pour les LLMs » ou « LangChain pour le traitement intelligent de documents ». Ce framework vise à créer les fonctionnalités spécifiques nécessaires au traitement de documents, telles que la segmentation de documents volumineux et la classification avancée.
ExtractThinker Dernière situation du trafic
Nombre total de visites mensuelles
Pas de données disponibles
Taux de rebond
Pas de données disponibles
Nombre moyen de pages par visite
Pas de données disponibles
Durée moyenne de la visite
Pas de données disponibles
ExtractThinker Tendance des visites
Pas de données de visites disponibles
ExtractThinker Distribution géographique des visites
Pas de données de distribution géographique disponibles
ExtractThinker Sources de trafic
Pas de données de sources de trafic disponibles
