
近日,随着字节跳动旗下豆包大模型的商业化进程加速,以及其在全球 AI 领域的亮眼表现,“
")
”概念股成为资本市场的新宠,引发 AI 赛道新一轮的上涨行情。
近日,随着字节跳动旗下豆包大模型的商业化进程加速,以及其在全球 AI 领域的亮眼表现,“
”概念股成为资本市场的新宠,引发 AI 赛道新一轮的上涨行情。

近日,南京大学的研究团队与字节跳动、西南大学联合推出了一项创新技术 ——STAR(Spatial-Temporal Augmentation with Text-to-Video Models),旨在利用文本到视频模型,实现真实世界视频的超分辨率处理。该技术结合了时空增强方法,能够有效提高低分辨率视频的质量,尤其适用于在视频分享平台上下载的低清晰度视频。为了方便研究者和开发者使用,研究团队已经在 GitHub 上发布了 STAR 模型的预训练版本,包括 I2VGen-XL 和 CogVideoX-5B 两种型号,以及相关的推理代码。这些工具的推出标志着在视频处

在数字媒体快速发展的时代,视频质量的提高和恢复成为了一个备受关注的话题。视频内容制作的普及使得人们对视频质量的要求日益增加,然而,许多视频在生成或传输过程中往往会受到各种因素的影响,导致画面模糊、细节缺失等问题。为了解决这一难题,南洋理工大学与字节跳动的研究团队近期推出了一款名为 SeedVR 的创新视频恢复技术。SeedVR 采用了前沿的扩散变换器(Diffusion Transformer)模型,旨在应对现实世界中视频恢复面临的各种挑战。传统的视频恢复方法在面对不同的分辨率

近日,字节跳动公司宣布推出一种名为 INFP 的人工智能系统,能够让静态的人物肖像照片通过音频输入实现 “说话” 和反应。与传统技术不同,INFP 无需手动指定说话和倾听的角色,系统可以根据对话的流动自动判断角色。INFP 的工作流程分为两个主要步骤。第一步,称为 “基于运动的头部模仿”,该系统通过分析人们在对话中的面部表情和头部运动,从视频中提取细节。这些运动数据会被转化为可以用于后续动画的格式,使静态照片能够与原始人物的运动相匹配。第二步是 “音频引导
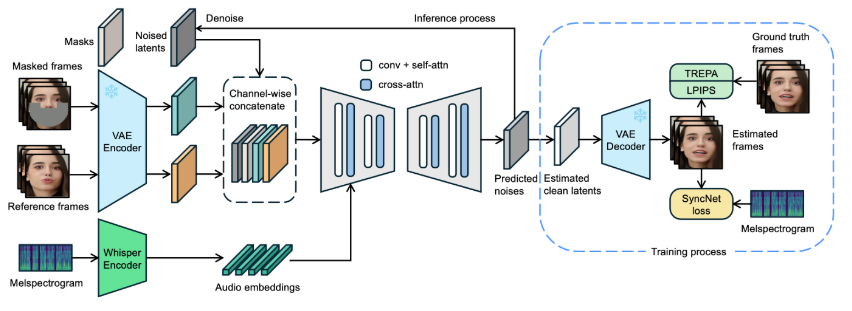
近日,字节跳动发布了名为 LatentSync 的新型口型同步框架,旨在利用音频条件潜在扩散模型实现更精确的口型同步。该框架基于Stable Diffusion,针对时间一致性做了优化。与以往的基于像素空间扩散或两阶段生成的方法不同,LatentSync 采用端到端的方式,无需中间运动表示,能够直接建模复杂的音频与视觉之间的关系。在 LatentSync 的框架中,首先使用 Whisper 将音频频谱图转换为音频嵌入,并通过交叉注意力层将其集成到 U-Net 模型中。框架通过将参考帧和掩码帧与噪声潜在变量进行通道级拼接