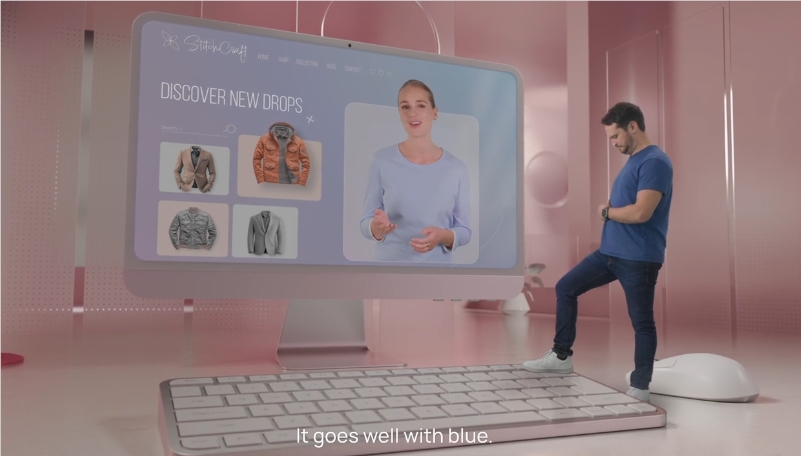
近日,一项名为INFP(Interactive, Natural, Flash and Person-generic)的新技术引起了广泛关注。这项技术旨在解决当前AI虚拟头像在双人对话中存在的互动不足问题,让虚拟人物在对话时能像真人一样,根据对话内容动态调整表情和动作。

告别“单口相声”,迎接“双人合唱”
以前的AI头像,要么只能自说自话,像个“单口相声”演员,要么就是只会傻傻地听着,没有任何反馈,像个“木头人”。但是,我们人类的对话可不是这样的!我们说话的时候,眼睛会看着对方,还会不时点头、皱眉,甚至插科打诨一下,这才是真正的互动啊!
而INFP的出现,就是要彻底改变这种尴尬的局面!它就像一个“双人合唱”的指挥家,能根据你和AI的对话音频,动态地调整AI头像的表情和动作,让你感觉就像在和真人对话一样!
INFP的“独门秘籍”:两大绝招,缺一不可!
INFP之所以这么厉害,主要归功于它的两大“独门秘籍”:
动作模仿大师 (Motion-Based Head Imitation):
它会先从大量的真实对话视频中学习人类的表情和动作,就像一个“动作模仿大师”,把这些复杂的行为压缩成一个个“动作密码”。
为了让动作更真实,它还会特别关注眼睛和嘴巴这两个“表情担当”,就像给它们上了“特写镜头”一样。
它还会使用人脸关键点来辅助表情的生成,确保动作的准确性和自然性。
然后,它把这些“动作密码”应用到一个静态的头像上,让头像瞬间“活”过来,简直就像魔法一样!
音频驱动的动作生成器 (Audio-Guided Motion Generation):
这个“生成器”更厉害,它能听懂你和AI的对话音频,就像一个“听声辨位”的高手。
它会分析音频中谁在说话、谁在听,然后动态调整AI头像的状态,让它在“说”和“听”之间自由切换,完全不用手动切换角色。
它还配备了两个“记忆库”,分别储存“说话”和“听”时的各种动作,就像两个“百宝箱”,随时提取最合适的动作。
它还能根据你的声音风格,调整AI头像的情绪和态度,让对话更生动有趣。
最后,它还会利用一种叫做“扩散模型”的技术,把这些动作变成平滑自然的动画,让你感觉不到任何卡顿。
DyConv:一个充满“八卦”的超大对话数据集!
为了训练INFP这个“超级AI”,研究人员还特意收集了一个超大规模的对话数据集,名叫 DyConv!
这个数据集里,有超过200小时的对话视频,里面的人来自五湖四海,聊的内容也是五花八门,简直就是个“八卦集中营”。
DyConv数据集的视频质量非常高,确保每个人的脸都清晰可见。
研究人员还使用了最先进的语音分离模型,把每个人的声音都单独提取出来,方便AI学习。
INFP的“十八般武艺”:不仅能对话,还能...
INFP不仅能在双人对话中大显身手,还能在其他场景中发光发热:
“听话”模式 (Listening Head Generation):它可以根据对方的说话内容,做出相应的表情和动作,就像一个“认真听讲”的好学生。
“复读机”模式 (Talking Head Generation):它可以根据音频,让头像做出逼真的口型,就像一个“口技表演”大师。
为了证明INFP的强大,研究人员进行了大量的实验,结果表明:
在各种指标上,INFP都碾压了其他同类方法,例如在视频质量、唇音同步和动作多样性等方面,都取得了非常优异的成绩。
在用户体验方面,参与者也一致认为,INFP生成的视频更加自然、生动,而且与音频的匹配度更高。
研究人员还做了消融实验,证明了 INFP 中的每个模块都是必不可少的。
项目地址:https://grisoon.github.io/INFP/