
相关AI新闻推荐

小红书开源的语音识别模型FireRedASR,中文识别准确率优越
在语音识别领域,中文识别的技术发展一直备受关注。近日,小红书的 FireRed 团队发布了一个全新的开源语音识别模型 ——FireRedASR。这个基于大模型的语音识别系统在多个标准测试集上取得了优异的成绩,标志着中文语音识别技术的一次重大突破。FireRedASR 的核心指标是字错误率(CER),该指标越低,表示模型的识别效果越好。在最近的公开测试中,FireRedASR 的 CER 达到了3.05%,较之前的最佳模型 Seed-ASR 降低了8.4%。这一结果显示出 FireRed 团队在语音识别技术上的创新能力。FireRedASR 模型分

豆包大模型发布2024年8个关键瞬间:从AI新星到全面突破
今日,豆包大模型官方发布豆包大模型的8个关键时刻!自2024年5月15日首次亮相以来,豆包大模型已破土而出,历经230天加速成长。从初步的学语,到懵懂的世界探索,再到为创作者绘制奇幻梦境,这一路的每一步都充满了挑战与成就。1. 语音识别与情感表达的突破豆包大模型在7月实现了语音识别领域的一大突破:能听懂超过20种方言的混合对话,并且具备边听边思考的能力。不仅如此,它还学会了在对话中表达情感,能在交互中自如地插话,甚至保留吞音和口音等人类语言习惯。这背后的核
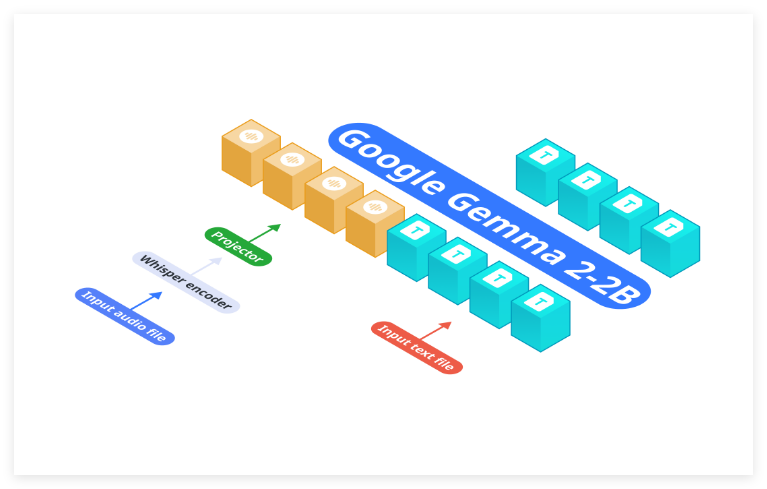
Nexa AI 发布 OmniAudio-2.6B:用于边缘部署的快速音频语言模型
Nexa AI近日推出了其全新的OmniAudio-2.6B音频语言模型,旨在满足边缘设备的高效部署需求。与传统的将自动语音识别(ASR)和语言模型分开的架构不同,OmniAudio-2.6B将Gemma-2-2b、Whisper Turbo以及定制的投影仪集成到一个统一框架中,这一设计消除了传统系统中各个组件链接所带来的低效率和延迟,特别适用于计算资源有限的设备。主要亮点:处理速度: OmniAudio-2.6B在性能上表现出色。在2024Mac Mini M4Pro上,使用Nexa SDK并采用FP16GGUF格式时,模型可实现每秒35.23个令牌的处理速度,而在Q4_K_M GGUF格式下,

新开源语音识别模型Moonshine:速度比OpenAI Whisper快五倍
美国初创公司 Useful Sensors 推出了一款名为 Moonshine 的开源语音识别模型。Moonshine 的设计旨在更高效地处理音频数据,相比于 OpenAI 的 Whisper,它在计算资源的使用上更为经济,处理速度快五倍。这一新模型专为在资源有限的硬件上实现实时应用而打造,具有灵活的架构。与 Whisper 将音频分为固定的30秒片段处理不同,Moonshine 根据实际音频长度调整处理时间。这使得它在处理较短音频片段时表现出色,减少了由于零填充而产生的处理开销。Moonshine 有两个版本:小型的 Tiny 版本参数量为2710万,