
相关AI新闻推荐

新型人工智能工具有望提前预测大脑退化,或将彻底改变痴呆症治疗
近日,麻省总医院及布里根妇女医院的研究人员开发了一款革命性的人工智能(AI)工具,能够提前数年预测患者的大脑退化,进而为早期治疗提供机会。这项研究的成果发表于《阿尔茨海默病杂志》,并显示该 AI 工具通过分析睡眠期间的大脑活动微妙变化,使用脑电图(EEG)进行预测。研究团队对281名在初次睡眠研究时认知功能正常的65岁以上女性进行了为期五年的追踪观察。在第二轮评估时,96名参与者发展为认知障碍。研究人员提取了 EEG 数据中的脑电波模式,利用 AI 检测深度睡眠期间

广州算力中心接入阿里通义千问大模型QwQ-32B
广州人工智能公共算力中心宣布成功适配并上线阿里通义千问的最新开源推理模型 ——QwQ-32B。这一模型在多个领域的权威评测中表现出色,尤其在数学、编程和通用能力等方面,其性能与满血版671B 的 DeepSeek-R1模型相当,明显超越了 o1-mini 及同尺寸的 R1蒸馏模型。据了解,QwQ-32B 模型由阿里巴巴开发,其开源性质使得更多的开发者和企业能够访问并使用这一技术。通过这一模型,用户可以在各种应用场景中实现更高效的自动化处理,例如自然语言处理、代码生成和数学计算等。这些

广东出台新政策: 12 项措施推动 AI与机器人产业创新发展
近日,广东省人民政府办公厅正式发布了推动人工智能与机器人产业创新发展的若干政策措施,旨在促进该领域的技术进步与企业成长。政策包括12项具体措施,覆盖技术攻关、企业培育、应用场景、产业集聚等多个方面。政策明确支持关键核心技术的攻关,鼓励企业、高校及科研机构联合开展创新活动,围绕人工智能与机器人产业链建立创新联盟。此外,省财政将对符合条件的重大专项项目给予资金支持,其中单个项目的省级配套金额可超过1亿元。广东省还将培育优质企业,鼓励企业整
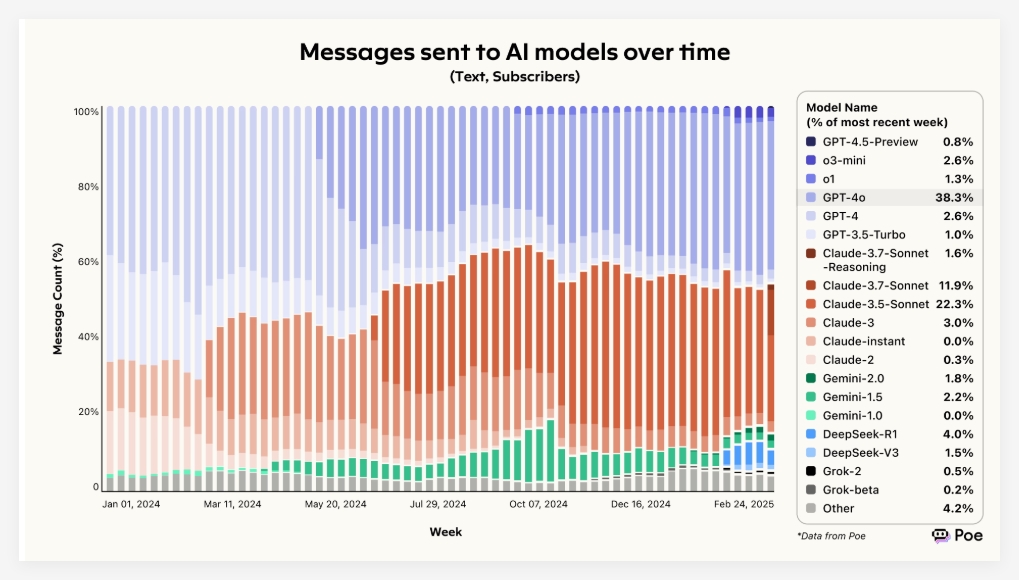
2025年AI市场大洗牌:DALL-E市占率暴跌80%,黑森林实验室崛起
根据最新数据显示,2025年的人工智能市场正在经历剧烈的变化,企业和消费者对人工智能工具的使用方式也发生了快速转变。Poe,一个汇聚了超过100种 AI 模型的平台,发布了一份综合报告,揭示了过去一年用户交互的使用模式,提供了关于文本、图像和视频生成技术的深入见解。Poe 的分析基于数百万用户的互动数据,给技术决策者提供了关键的市场洞察。在这一快速发展的生态系统中,使用数据往往是被严密保密的。Poe 在报告中指出,随着 AI 模型的不断进步,它们将逐步成为人们获取