全球最大开源翻译模型!Meta 出品,支持 100 种语音、语言!
微信公众平台
80
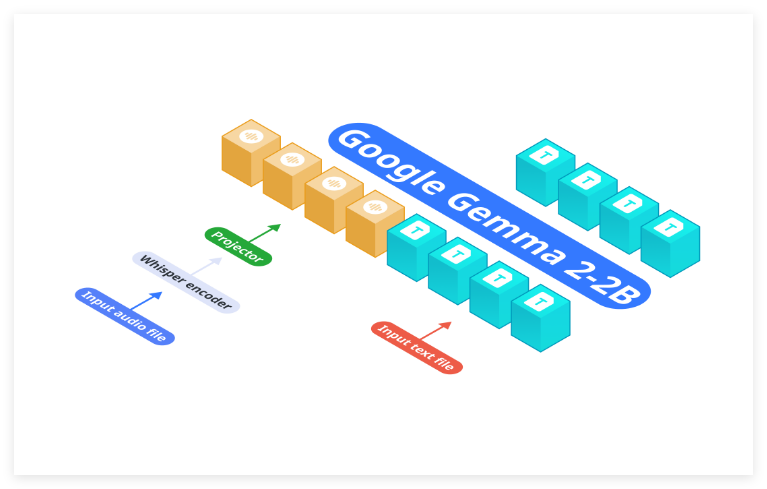
Meta 开源了全球最大的多模式翻译大模型 SeamlessM4T,支持 100 种语言,并能识别地方语言。该模型能执行语音到文本、语音到语音、文本到语音和文本到文本的多模式翻译任务。SeamlessM4T 集成了 Meta 之前发布的 NLLB、MMS 等翻译模型,并使用了大量的语音和文本对齐数据进行训练。该模型在多任务翻译中取得了先进的结果,并在鲁棒性测试中表现出色,尤其是对于背景噪声和说话人变化的识别。同时,该模型显著提高了中低资源语言的性能。
© 版权所有 AIbase基地 2024, 点击查看来源出处 - https://www.aibase.com/zh/news/764