
2025-02-20 09:14:14.AIbase.
AI大语言模型幻觉排行榜:Gemini 2.0 Flash幻觉最低

2025-02-18 16:55:26.AIbase.
OpenAI 推出 SWE-Lancer 基准测试:评估真实世界自由软件工程工作的模型性能

2025-01-16 10:42:26.AIbase.
阿里巴巴Qwen 团队发布新型过程奖励模型,数学推理再进化

2024-12-26 09:58:14.AIbase.
人工智能解说足球赛:可以识别犯规、评估严重程度并对进行评论

2024-12-19 14:07:19.AIbase.
AI并非万能:最新研究揭示顶尖AI模型出现类似早期痴呆的认知障碍

2024-12-19 09:21:18.AIbase.
谷歌Gemini正在迫使外包人员评估专业领域外的 AI 响应

2024-12-15 10:23:35.AIbase.
阿里推新 AI 基准测试 “PROCESSBENCH”,评估数学推理中的错误识别能力

2024-12-05 14:45:53.AIbase.
字节开源全新代码大模型评估基准“FullStack Bench”

2024-09-30 14:08:02.AIbase.
智源研究院推出全球首个中文大模型辩论平台FlagEval Debate

2024-09-29 15:33:05.AIbase.
Salesforce AI 推全新大语言模型评估家族SFR-Judge 基于Llama3构建

2024-09-10 11:03:27.AIbase.
AI 评估不再难!Hugging Face 推出 LightEval,让你轻松掌控模型表现!

2024-08-16 14:03:40.AIbase.
Geekbench 推出新AI基准测试,评估设备处理AI任务的性能
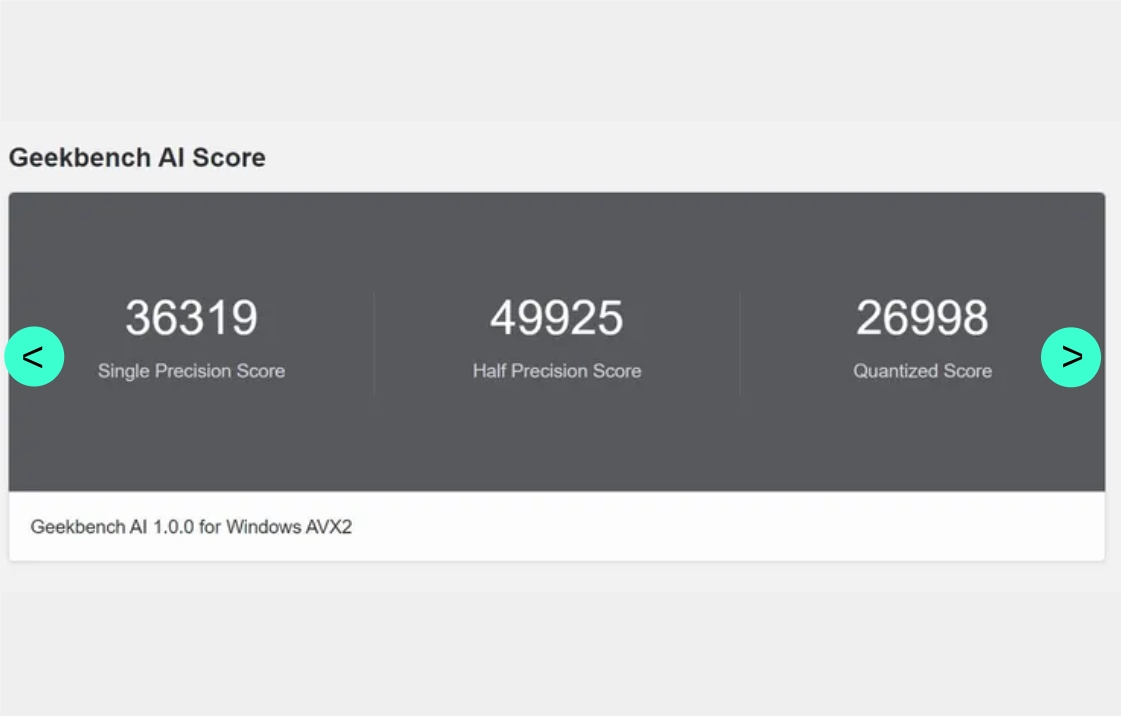
2024-08-16 09:50:38.AIbase.
Geekbench推出AI性能测试工具:设备AI能力评估迎来新标准

2024-08-15 14:53:25.AIbase.
OpenAI推出SWE-bench Verified:提升AI软件工程能力评估
2024-08-09 09:16:52.AIbase.
OpenAI 表示其最新的 GPT-4o 模型风险评级为“中等”

2024-08-07 14:14:43.AIbase.
Meta推“自学评估器”: 无需人工注释NLP模型评估,优于 GPT-4 等常用的LLM
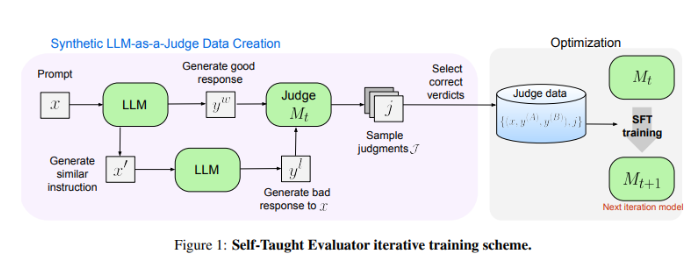
2024-07-18 09:09:48.AIbase.
蚂蚁集团联合新京报发布大模型产品“贝壳财经·智引ESG”

2024-07-12 11:10:22.AIbase.
OpenAI首次披露AGI评估标准:ChatGPT仅为第一级

2024-07-10 08:39:22.AIbase.
Anthropic推出提示词评估工具 帮助开发者更快、更高效地优化提示词质量
2024-07-02 09:07:20.AIbase.
