
Typ :
- Nachrichten und Informationen
- Produktanwendungen
- Monetarisierungsfälle
- KI-Tutorials
2024-09-25 13:54:53.AIbase.12.0k
智源研究院发布中文互联网语料库CCI 3.0,包含 1000 GB 数据集
Auf dem Beijing Culture Forum 2024 gab das Beijing Academy of Artificial Intelligence (BAAI) die offizielle Veröffentlichung des CCI 3.0 (Chinese Corpora Internet), der neuen Generation des chinesischen Internet-Korpus, bekannt. Dies fördert die gemeinsame Nutzung und den Aufbau von Daten weiter. CCI 3.0 umfasst einen Datensatz von 1000 GB und einen 498 GB großen hochwertigen Subset CCI 3.0-HQ. Dies ist nach der erstmaligen Open-Source-Veröffentlichung von CCI 1.0 im November 2023 und der Veröffentlichung von CCI 2.0 im April 2024 ein weiteres wichtiges Update.

2024-09-05 08:43:35.AIbase.11.5k
智源研究院推出包含文生视频模型对战评测服务:FlagEval大模型角斗场
Am 4. September 2024 gab das Beijing Academy of Artificial Intelligence (BAAI) die Einführung von FlagEval, der weltweit ersten Modell-Battle- und Bewertungsdienstleistung mit Text-zu-Video-Funktionen, bekannt. Dieser Service steht Nutzern offen und umfasst etwa 40 große Sprachmodelle aus dem In- und Ausland. Er unterstützt benutzerdefinierte Online- oder Offline-Bewertungen für vier Aufgaben: Sprachfragen und Antworten, multimodalen Bild- und Textverständnis, Text-zu-Bild und Text-zu-Video.
2024-07-25 16:44:09.AIbase.10.6k
智源研究院发布全球首个万亿参数稠密模型 Tele-FLM-1T (开源)
Das Beijing Institute for Artificial Intelligence (BAAI) und das China Telecom Artificial Intelligence Research Institute haben gemeinsam die aktualisierte Version der Tele-FLM-Serie großer Sprachmodelle vorgestellt, darunter das 52B-Parameter-Instruktionsmodell FLM-2-52B-Instruct und das Trillion-Parameter-Modell Tele-FLM-1T. FLM-2-52B-Instruct wurde durch Instruktions-Feinabstimmung optimiert, um die Fähigkeiten im chinesischen Dialog zu verbessern und erreicht 90% des Niveaus von GPT-4. Es basiert auf dem Tele-FLM-52B-Basismodell und verwendet einen spezifischen Datensatz und Parameteroptimierung. Tele-FLM-1T...

2024-07-17 13:47:02.AIbase.10.3k
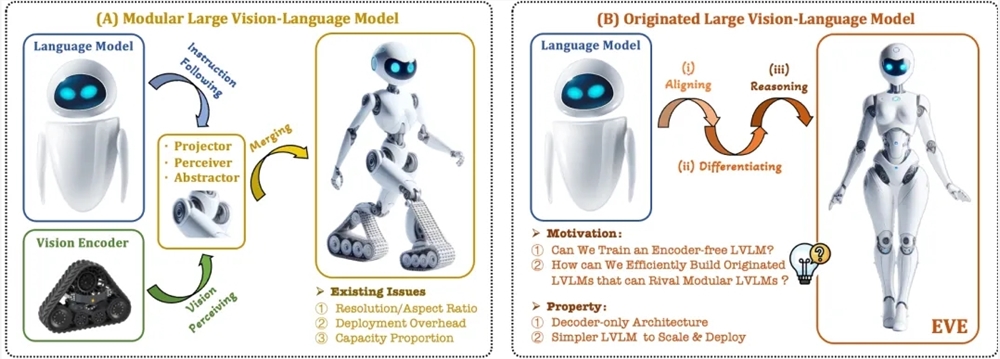
智源研究院发布新一代无编码器视觉语言多模态大型模型EVE
Die Forschung und Anwendung multimodaler großer Sprachmodelle hat in letzter Zeit bemerkenswerte Fortschritte erzielt. Ausländische Unternehmen wie OpenAI, Google und Microsoft haben eine Reihe fortschrittlicher Modelle vorgestellt, und auch in China haben Institutionen wie Zhihu AI und Jieyue Xingchen in diesem Bereich Durchbrüche erzielt. Diese Modelle verlassen sich üblicherweise auf visuelle Encoder, um visuelle Merkmale zu extrahieren und sie mit großen Sprachmodellen zu kombinieren. Dies führt jedoch zu einem Problem der visuellen induktionsbedingten Verzerrung durch getrennte Schulung, was die Implementierungseffizienz und die Leistung multimodaler großer Sprachmodelle einschränkt.
2023-12-25 14:12:47.AIbase.4.5k
智源研究院发布代码生成训练数据集 TACO
Das Institut für Künstliche Intelligenz (AI) hat einen neuen Trainingsdatensatz für die Codegenerierung namens TACO veröffentlicht. Dieser soll Codegenerierungsmodellen herausforderndere Trainingsdaten und Benchmarks bieten. TACO zeichnet sich durch seine Datenmenge, Qualität und Bewertungsmethoden aus, darunter größere Trainings- und Testdatensätze, diverse Lösungsansätze und detaillierte Labels. Experimentelle Ergebnisse zeigen signifikante Unterschiede zwischen aktuellen Codegenerierungsmodellen und GPT-4 in der TACO-Bewertung, was darauf hindeutet, dass in diesem Bereich noch Verbesserungspotential besteht. TACO...
2023-12-22 08:58:36.AIbase.4.4k
智源研究院发布 Emu2:Neues generationsübergreifendes multimodalen Basismodell
Das Beijing Academy of Artificial Intelligence hat ein neues generationsübergreifendes multimodalen Basismodell, Emu2, veröffentlicht, das die Fähigkeiten des multimodalen kontextuellen Lernens vorantreibt. Emu2 übertrifft Flamingo-80B und IDEFICS-80B und zeigt eine hervorragende Leistung bei multimodalen Verständnisaufgaben mit wenigen Beispielen. Emu2 erreicht die beste Leistung bei mehreren Aufgaben zum Verständnis mit wenigen Beispielen, bei der Beantwortung visueller Fragen und bei der Bilderzeugung. Emu2-Chat ermöglicht ein präzises Verständnis von Bild- und Textanweisungen, während Emu2-Gen eine flexible, kontrollierbare und qualitativ hochwertige Bild- und Videoerzeugung ermöglicht.
2023-11-29 14:00:10.AIbase.3.7k
智源研究院携手共建中文互联网语料库 CCI,助力大数据与人工智能领域
Das Forschungsinstitut für künstliche Intelligenz (AI) Zhiyuan hat zusammen mit Topos und Zhongke Wenge das "Chinese Internet Corpus" (CCI) erstellt. Dieser sorgfältig kuratierte und bereinigte Datensatz umfasst 104 GB und deckt den Zeitraum von 2001 bis 2023 ab. Zhiyuan wird die Datenquellen weiter ausbauen und die Datenverarbeitungsprozesse optimieren, um qualitativ hochwertige und zuverlässige Daten bereitzustellen. Zusätzlich bietet Zhiyuan weitere hochwertige chinesische Datensätze wie WUDAO Corpora, COIG und MTP an. Diese Initiative zielt darauf ab,...
2023-11-13 08:59:01.AIbase.3.1k
智源研究院开源 JudgeLM Bewertungsmodell zur Bewertung verschiedener großer Sprachmodelle und Ausgabe von Bewertungen
Das Forschungsinstitut für künstliche Intelligenz (AI) 智源研究院 hat das JudgeLM Bewertungsmodell veröffentlicht, das verschiedene große Sprachmodelle effizient bewertet und Bewertungen ausgibt. JudgeLM kostet im Vergleich zu GPT-4 nur 1/120 und erreicht eine Übereinstimmung der Ergebnisse von über 90 %. JudgeLM kann in verschiedenen Bewertungsszenarien wie reinem Text und multimodalen Szenarien eingesetzt werden und gibt Bewertungen und Begründungsgrundlagen aus. Die Übereinstimmung von JudgeLM mit den Referenzantworten liegt bei über 90 % und nähert sich der menschlichen Leistung an. 智源研究院 hat die Trainings- und Validierungsdaten veröffentlicht.
2023-10-20 14:22:29.AIbase.2.3k
智源研究院开源 10 亿参数三维视觉通用模型 Uni3D
Das Beijing Academy of Artificial Intelligence (BAAI) hat kürzlich das Uni3D-Modell veröffentlicht, ein universelles 3D-Vision-Modell mit 1 Milliarde Parametern. Dieses Modell kann Punktwolken verarbeiten und hat bei wichtigen 3D-Vision-Aufgaben Durchbrüche erzielt. Uni3D verwendet eine einheitliche Transformer-Architektur und führt eine multimodale Alignments-Trainingsmethode ein. Das Modell erzielte in verschiedenen 3D-Vision-Aufgaben State-of-the-Art-Ergebnisse. Das BAAI gab bekannt, dass die Open-Source-Veröffentlichung von Uni3D die zukünftige Forschung im Bereich der 3D-Computer Vision unterstützen wird.
2023-09-28 10:03:16.AIbase.1.8k
智源研究院发布开源 AI 硬件评测引擎 FlagPerf v1.0
Das Forschungsinstitut für künstliche Intelligenz (AIRS) veröffentlicht die Open-Source-KI-Hardware-Benchmarking-Engine FlagPerf v1.0.
FlagPerf-Kennzahlen umfassen funktionale Korrektheit, Leistung, Ressourcenverbrauch und Ökosystem-Kompatibilität.
Unterstützung für verschiedene Trainings-Frameworks und Inferenz-Engines sowie verschiedene Testumgebungen.
Strenge Überprüfung des eingereichten Codes für faire und objektive Ergebnisse.
Der Testcode wurde Open Source veröffentlicht; der Testprozess und die Daten sind reproduzierbar.
2023-09-18 11:23:15.AIbase.1.4k
智源发布全球最大的中文和英文语义向量模型训练数据集 MTP
Das Forschungsinstitut für künstliche Intelligenz (Beijing Academy of Artificial Intelligence, BAAI) hat mit MTP den weltweit größten Trainingsdatensatz für semantische Vektormodelle in Chinesisch und Englisch veröffentlicht. Der Datensatz umfasst 300 Millionen Paare. MTP ist der größte öffentlich zugängliche Datensatz mit korrelierenden chinesischen und englischen Texten und bildet eine wichtige Grundlage für das Training semantischer Vektormodelle. Der Datensatz enthält chinesisch-englische Textpaare aus verschiedenen Quellen, darunter Frage-Antwort-Paare, Kommentare und Nachrichten. Das BAAI betont die entscheidende Rolle des Datensatzes für das Training großer Modelle und seine Bedeutung für die Förderung gemeinsamer Innovationen im Bereich der künstlichen Intelligenz. Die Veröffentlichung dieses Datensatzes dürfte die Herausforderungen bei der Entwicklung und dem Training von Modellen für die chinesische Sprache angehen.