
Tipo :
- Información de Noticias
- Aplicaciones de Productos
- Casos de Monetización
- Tutoriales de IA
2024-12-26 09:25:57.AIbase.14.3k
腾讯研究推出新型翻译模型 DRT-o1,重塑文学文本翻译
Con la profundización de la globalización, la tecnología de traducción automática neuronal (TAN) desempeña un papel cada vez más importante en el intercambio interlingüístico. Si bien las herramientas de traducción actuales muestran un excelente rendimiento en el procesamiento de documentos técnicos y textos simples, todavía enfrentan numerosos desafíos en la traducción de textos literarios. Las obras literarias a menudo contienen metáforas y símiles, expresiones ricas en matices culturales y emocionales, que los sistemas de traducción tradicionales suelen tener dificultades para transmitir con precisión su significado profundo. Para compensar esta deficiencia, el equipo de investigación de Tencent ha lanzado un nuevo sistema de traducción llamado DRT-o1. Este sistema incluye

2024-09-05 08:43:35.AIbase.11.5k
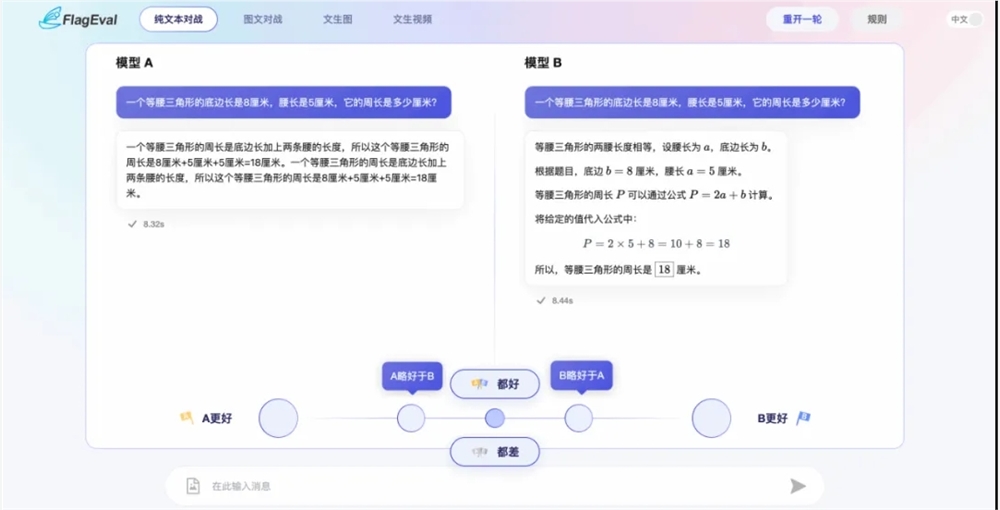
智源研究院推出包含文生视频模型对战评测服务:FlagEval大模型角斗场
El 4 de septiembre de 2024, el Instituto de Inteligencia Artificial de Beijing (BAAI) anunció el lanzamiento de FlagEval, el primer servicio de evaluación de modelos de confrontación a nivel mundial que incluye la generación de vídeo a partir de texto. Este servicio está abierto a los usuarios, cubre aproximadamente 40 modelos grandes nacionales e internacionales, y admite la evaluación personalizada en línea o fuera de línea de cuatro tareas principales: preguntas y respuestas en lenguaje natural, comprensión de imágenes y texto multimodales, generación de imágenes a partir de texto y generación de vídeo a partir de texto.
2024-07-25 16:44:09.AIbase.10.6k
智源研究院开源全球首个万亿单体稠密模型Tele-FLM-1T
El Instituto de Investigación de Inteligencia Artificial de Beijing Zhiyuan y el Instituto de Investigación de Inteligencia Artificial de China Telecom se han asociado para lanzar una versión mejorada de la serie de grandes modelos Tele-FLM, que incluye el modelo de instrucciones FLM-2-52B-Instruct y el modelo de billones de parámetros Tele-FLM-1T. FLM-2-52B-Instruct, mediante el ajuste de instrucciones, se centra en mejorar la capacidad de conversación en chino, alcanzando el 90% del nivel de GPT-4. Se basa en el modelo base Tele-FLM-52B y utiliza un conjunto de datos específico y optimización de parámetros. Tele-F

2024-07-17 13:47:02.AIbase.10.3k
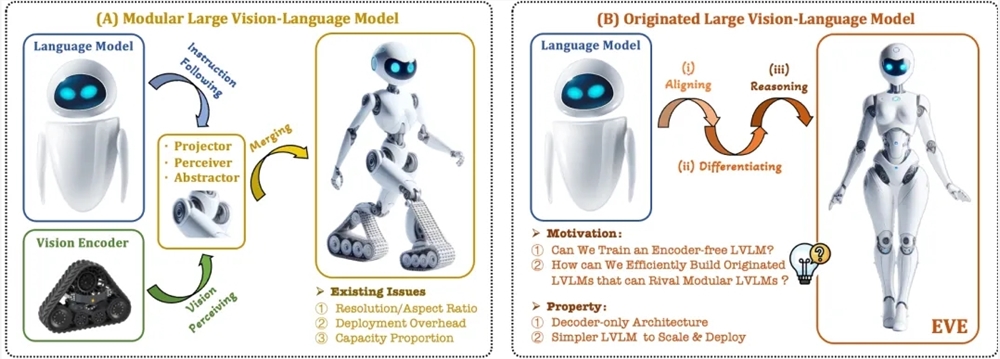
智源研究院推出新一代无编码器视觉语言多模态大模型EVE
Recientemente, la investigación y aplicación de modelos multimodales de gran envergadura han experimentado un progreso notable. Empresas extranjeras como OpenAI, Google y Microsoft han lanzado una serie de modelos avanzados, y en China, instituciones como Zhipu AI y Jieyue Xingchen también han logrado avances en este campo. Estos modelos suelen depender de codificadores visuales para extraer características visuales y combinarlas con modelos de lenguaje de gran envergadura, pero presentan el problema de sesgo de inducción visual debido a la separación del entrenamiento, lo que limita la eficiencia y el rendimiento del despliegue de los modelos multimodales de gran envergadura.
2023-10-20 14:22:29.AIbase.2.3k
智源研究院开源10亿参数三维视觉通用模型Uni3D
El Instituto de Inteligencia Artificial de Beijing (Beijing Academy of Artificial Intelligence, BAAI) ha publicado recientemente el modelo Uni3D, un modelo de visión 3D de propósito general con 1000 millones de parámetros. Este modelo puede procesar datos de nubes de puntos y ha logrado avances significativos en las principales tareas de visión 3D. Uni3D utiliza una arquitectura Transformer unificada e introduce un método de entrenamiento de alineación multimodal. Este modelo ha obtenido resultados de vanguardia en diversas tareas de visión 3D. El Instituto de Inteligencia Artificial de Beijing afirma que la publicación de código abierto de Uni3D allana el camino para futuras investigaciones en visión artificial 3D.
2023-09-28 10:03:16.AIbase.1.8k
智源研究院发布开源 AI 硬件评测引擎 FlagPerf v1.0
El Instituto de Inteligencia Artificial de Beijing (BAAI) lanza FlagPerf v1.0, un motor de evaluación de hardware de IA de código abierto. FlagPerf incluye métricas de evaluación que abarcan la corrección funcional, el rendimiento, el uso de recursos y la adaptación del ecosistema. Admite múltiples frameworks de entrenamiento e inferencia, así como diversos entornos de prueba. Se revisa estrictamente el código presentado para garantizar resultados justos e imparciales. El código de prueba se ha publicado como código abierto, y el proceso de prueba y los datos son reproducibles.