今年春节开始,全网开始流行跳“铁山靠”的小猫咪。背后的技术是阿里巴巴通义实验室发布的AI动画项目AnimateAnyone,只需一张静态图片结合骨骼动画,即可生成人物动画视频。这款AI项目与其他有何不同?
相关AI新闻推荐

阿里通义万相首尾帧生视频模型Wan2.1-FLF2V-14B开源
阿里巴巴旗下的通义实验室在Hugging Face和GitHub平台正式开源了其最新的Wan2.1-FLF2V-14B首尾帧生视频模型。这一模型以其支持高清视频生成和灵活的首尾帧控制功能引发业界热议,为AI驱动的视频创作提供了全新可能。Wan2.1-FLF2V-14B:首尾帧驱动的视频生成新标杆Wan2.1-FLF2V-14B是阿里通义万相系列的最新力作,基于数据驱动训练和**DiT(Diffusion Transformer)**架构,专为首尾帧视频生成设计。据社交媒体平台上的讨论,该模型只需用户提供两张图片作为首帧和尾帧,即可生成一段长约5秒、720p分辨率的
2025年4月18号 10:52
1.2k
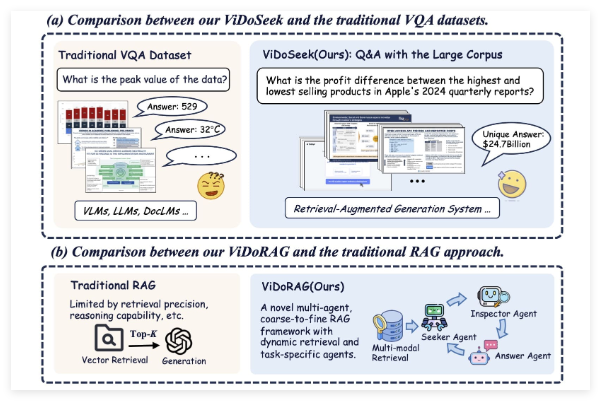
阿里通义实验室开源视觉文档RAG系统ViDoRAG,准确率达79.4%
近日,阿里巴巴通义实验室宣布开源其最新研发成果——ViDoRAG,这是一款专为视觉文档理解设计的检索增强生成(RAG)系统。ViDoRAG在GPT-4o模型上的测试显示,其准确率达到了令人瞩目的79.4%,相较传统RAG系统提升了10%以上。这一突破标志着视觉文档处理领域迈出了重要一步,为人工智能在复杂文档理解上的应用提供了新的可能性。多智能体框架赋能视觉文档理解ViDoRAG并非传统的单一模型,而是采用了创新的多智能体框架设计。据介绍,该系统结合了动态迭代推理代理(Dynamic Iterative Reason
2025年3月3号 16:29
6.2k
阿里巴巴通义实验室开源 AI 图像生成微调框架 SCEdit
["阿里通义实验室开源 AI 图像生成微调框架 SCEdit","SCEdit 框架支持图像生成任务的微调","SCEdit 框架在生成任务中具有高效性能","SCEdit 框架在可控生成任务中实现精准控制","SCEdit 框架节省训练显存开销"]
2024年1月5号 9:00
800