आजकल कृत्रिम बुद्धिमत्ता (आर्टिफिशियल इंटेलिजेंस - AI) तकनीक बहुत तेज़ी से विकसित हो रही है। ऐसे में विभिन्न जनरेटिव AI मॉडलों की क्षमता का प्रभावी ढंग से मूल्यांकन और तुलना करना एक बड़ी चुनौती बन गया है। पारंपरिक AI बेंचमार्किंग विधियाँ अपनी सीमाएँ दिखा रही हैं, इसलिए AI डेवलपर्स नए और रचनात्मक मूल्यांकन तरीके खोज रहे हैं।
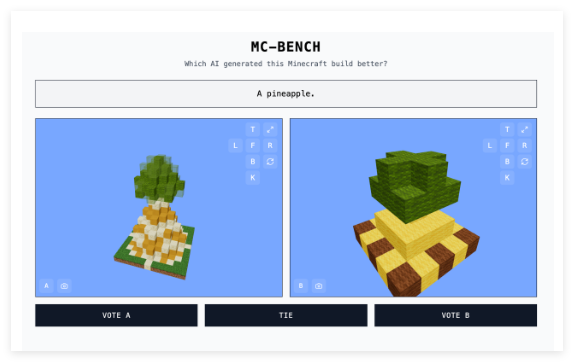
हाल ही में, "Minecraft Benchmark" (संक्षेप में MC-Bench) नामक एक वेबसाइट सामने आई है। इसकी खासियत यह है कि यह माइक्रोसॉफ्ट के सैंडबॉक्स निर्माण गेम "माइनक्राफ्ट" (Minecraft) को प्लेटफ़ॉर्म के रूप में इस्तेमाल करती है। यहाँ यूज़र्स AI मॉडल द्वारा दिए गए निर्देशों के अनुसार बनाए गए गेम वर्क्स की तुलना करके उनके प्रदर्शन का मूल्यांकन कर सकते हैं। और सबसे आश्चर्यजनक बात यह है कि इस नए प्लेटफ़ॉर्म को 12वीं कक्षा के एक छात्र ने बनाया है।

"माइनक्राफ्ट" AI का युद्ध-क्षेत्र बन गया
MC-Bench वेबसाइट AI मॉडल के मूल्यांकन का एक सहज और रोचक तरीका प्रदान करती है। डेवलपर्स परीक्षण में शामिल AI मॉडल में विभिन्न निर्देश देते हैं, और मॉडल "माइनक्राफ्ट" में संबंधित संरचनाएँ बनाते हैं। यूज़र्स यह जाने बिना कि किस संरचना को किस AI मॉडल ने बनाया है, उन संरचनाओं को वोट कर सकते हैं और चुन सकते हैं कि कौन सी संरचना निर्देशों के अनुसार बेहतर है। वोटिंग के बाद ही यूज़र्स को प्रत्येक संरचना के पीछे के "निर्माता" के बारे में पता चलता है। यह "ब्लाइंड चॉइस" प्रणाली AI मॉडल की वास्तविक निर्माण क्षमता को अधिक निष्पक्ष रूप से दर्शाती है।
आदि सिंह ने बताया कि "माइनक्राफ्ट" को बेंचमार्किंग प्लेटफ़ॉर्म के रूप में चुनने का कारण केवल गेम की लोकप्रियता नहीं है - यह अब तक का सबसे अधिक बिका हुआ इलेक्ट्रॉनिक गेम है। इससे भी ज़्यादा महत्वपूर्ण बात यह है कि इस गेम का व्यापक प्रसार और इसके विज़ुअल स्टाइल से लोग परिचित हैं। इसलिए, इस गेम को नहीं खेलने वाले लोग भी आसानी से बता सकते हैं कि कौन सा ब्लॉक से बना अनानास ज़्यादा वास्तविक दिखता है। उनका मानना है कि "माइनक्राफ्ट" लोगों को [AI विकास] की प्रगति को आसानी से देखने में मदद करता है। यह दृश्य मूल्यांकन विधि केवल टेक्स्ट इंडिकेटर्स से ज़्यादा प्रभावशाली है।
कार्य केंद्रित
MC-Bench वर्तमान में अपेक्षाकृत सरल निर्माण कार्य करता है, जैसे कि "आइस किंग" या "एक आदिम समुद्र तट पर आकर्षक उष्णकटिबंधीय झोपड़ी" जैसे निर्देशों के अनुसार, AI मॉडल को संबंधित गेम संरचना बनाने के लिए कोड लिखने के लिए कहना। यह मूल रूप से एक प्रोग्रामिंग बेंचमार्क है, लेकिन इसकी चतुराई इस बात में है कि यूज़र्स को जटिल कोड में गहराई से जाने की ज़रूरत नहीं है। वे केवल दृश्य प्रभावों के आधार पर ही काम की गुणवत्ता का निर्णय कर सकते हैं। इससे परियोजना में भागीदारी और डेटा संग्रह की क्षमता बढ़ती है।
MC-Bench का डिज़ाइन लोगों को AI तकनीक के विकास के स्तर को अधिक स्पष्ट रूप से समझने में मदद करने के लिए है। सिंह ने कहा, "वर्तमान रैंकिंग मेरे द्वारा इन मॉडलों के उपयोग के अनुभव से पूरी तरह मेल खाती है, जो कई शुद्ध पाठ बेंचमार्क से अलग है।" उनका मानना है कि MC-Bench संबंधित कंपनियों को एक मूल्यवान संदर्भ प्रदान कर सकता है, जिससे उन्हें यह निर्णय लेने में मदद मिलेगी कि उनका AI अनुसंधान सही दिशा में है या नहीं।
हालांकि MC-Bench आदि सिंह द्वारा शुरू किया गया है, लेकिन इसके पीछे कई स्वयंसेवक भी हैं। उल्लेखनीय है कि Anthropic, Google, OpenAI और Alibaba जैसी कई शीर्ष AI कंपनियों ने बेंचमार्किंग चलाने के लिए अपने उत्पादों का उपयोग करने के लिए सब्सिडी प्रदान की है। हालाँकि, MC-Bench की वेबसाइट में कहा गया है कि ये कंपनियाँ अन्य किसी भी तरह से इस परियोजना से जुड़ी नहीं हैं।
MC-Bench के भविष्य के बारे में सिंह बहुत आशावादी हैं। उन्होंने कहा कि वर्तमान में किए जा रहे सरल निर्माण केवल एक शुरुआत है, और भविष्य में इसे और अधिक दीर्घकालिक योजनाओं और लक्ष्य-उन्मुख कार्यों तक विस्तारित किया जा सकता है। उनका मानना है कि गेम AI की "एजेंट रीज़निंग" क्षमता का परीक्षण करने के लिए एक सुरक्षित और नियंत्रित माध्यम हो सकता है, जो वास्तविक जीवन में मुश्किल है, इसलिए परीक्षण के मामले में यह अधिक लाभदायक है।
AI मूल्यांकन का एक नया और अभिनव तरीका
MC-Bench के अलावा, "स्ट्रीट फाइटर" और "पिक्शनरी" जैसे अन्य गेमों का भी AI के लिए प्रायोगिक बेंचमार्क के रूप में उपयोग किया गया है, जो दर्शाता है कि AI बेंचमार्किंग अपने आप में एक कुशल क्षेत्र है। पारंपरिक मानकीकृत मूल्यांकन में अक्सर "होम एडवांटेज" होता है, क्योंकि AI मॉडल को प्रशिक्षण के दौरान कुछ विशिष्ट प्रकार के प्रश्नों के लिए अनुकूलित किया जाता है, खासकर उन प्रश्नों में जहाँ रटने या बुनियादी निष्कर्ष निकालने की आवश्यकता होती है। उदाहरण के लिए, OpenAI का GPT-4 LSAT परीक्षा में 88% अंक प्राप्त करता है, लेकिन यह "strawberry" शब्द में कितने "R" हैं, यह नहीं बता सकता।

Anthropic का Claude 3.7 Sonnet मानकीकृत सॉफ्टवेयर इंजीनियरिंग बेंचमार्क में 62.3% की सटीकता प्राप्त करता है, लेकिन "पोकेमोन" खेलने में यह अधिकांश पाँच वर्षीय बच्चों से कम अच्छा प्रदर्शन करता है।
MC-Bench का आगमन जनरेटिव AI मॉडल की क्षमता का मूल्यांकन करने के लिए एक नया और अधिक समझने योग्य दृष्टिकोण प्रदान करता है। यह लोकप्रिय गेम प्लेटफ़ॉर्म का उपयोग करके जटिल AI तकनीकी क्षमताओं को सहज दृश्य तुलना में बदल देता है, जिससे अधिक लोग AI के मूल्यांकन और समझ में भाग ले सकते हैं। हालाँकि इस मूल्यांकन विधि का वास्तविक मूल्य अभी भी चर्चा में है, लेकिन इसमें कोई संदेह नहीं है कि यह हमें AI विकास को देखने के लिए एक नई खिड़की प्रदान करता है।