aiOS是 "hyperspaceai" 组织开发的世界首个基于 Mistral7B 模型的去中心化 AI 网络。它旨在彻底改变人工智能的可访问性,让用户能够体验到前沿的去中心化人工智能计算。目前该应用程序处于早期开发阶段,提供给 Windows、Linux 和 macOS 用户下载体验。目前已经支持Llama-3,用户可以免费体验。

据官方称,目前超过5000+节点,近期将会推出赚取积分服务。用户可以通过官方下载体验:https://aios.network/
aiOS是 "hyperspaceai" 组织开发的世界首个基于 Mistral7B 模型的去中心化 AI 网络。它旨在彻底改变人工智能的可访问性,让用户能够体验到前沿的去中心化人工智能计算。目前该应用程序处于早期开发阶段,提供给 Windows、Linux 和 macOS 用户下载体验。目前已经支持Llama-3,用户可以免费体验。
据官方称,目前超过5000+节点,近期将会推出赚取积分服务。用户可以通过官方下载体验:https://aios.network/
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
耶路撒冷希伯来大学的研究人员最近发现,在检索增强生成(RAG)系统中,即使总文本长度保持不变,处理的文档数量也会显著影响语言模型的性能。研究团队利用MuSiQue验证数据集中的2,417个问题进行实验,每个问题链接到20个维基百科段落。其中两到四段包含相关答案信息,其余段落作为干扰项。为研究文档数量的影响,团队创建了多个数据分区,逐步将文档数量从20个减少到最少只保留包含相关信息的2-4个文档。为确保总标记数一致,研究人员使用原始维基百科文章的文本扩展了保留

微软近期在 Hugging Face 平台上发布了名为 Phi-4的小型语言模型,这款模型的参数量仅为140亿,但在多项性能测试中表现出色,超越了众多知名模型,包括 OpenAI 的 GPT-4o 及其他同类开源模型如 Qwen2.5和 Llama-3.1。在之前的在美国数学竞赛 AMC 的测试中,Phi-4获得了91.8分,显著优于 Gemini Pro1.5、Claude3.5Sonnet 等竞争对手。更令人惊讶的是,这款小参数模型在 MMLU 测试中取得了84.8的高分,充分展现了其强大的推理能力和数学处理能力。与许多依赖于有机数据源的模型不同,Phi-4采用了创新的方法来生

近日,北京大学等科研团队宣布发布了一款名为 LLaVA-o1的多模态开源模型,据称这是首个能够进行自发、系统推理的视觉语言模型,堪比 GPT-o1。该模型在六个具有挑战性的多模态基准测试中表现优异,其11B 参数的版本超越了其他竞争者,如 Gemini-1.5-pro、GPT-4o-mini 和 Llama-3.2-90B-Vision-Instruct。LLaVA-o1基于 Llama-3.2-Vision 模型,采用了 “慢思考” 推理机制,能够自主进行更加复杂的推理过程,超越了传统的思维链提示方法。在多模态推理基准测试中,LLaVA-o1的表现超出了其基础模型8.9%。该模型的

Nvidia 悄然推出了一款新型人工智能模型,名为 Llama-3.1-Nemotron-70B-Instruct,表现出色,已经超越了 OpenAI 的 GPT-4和 Anthropic 的 Claude3.5,标志着人工智能领域竞争格局的重大变化。这款模型在知名 AI 平台 Hugging Face 上发布,虽然没有太大的宣传,但其卓越的性能迅速引起了业界的关注。根据 Nvidia 的报告,这款新模型在多项基准测试中获得了最高分,包括在 Arena Hard 基准测试中得分85.0、在 AlpacaEval2LC 中得分57.6、以及在 GPT-4-Turbo MT-Bench 中得分8.98。这些分数让 Nvidia 在 AI 语言理解和生成方面迅速
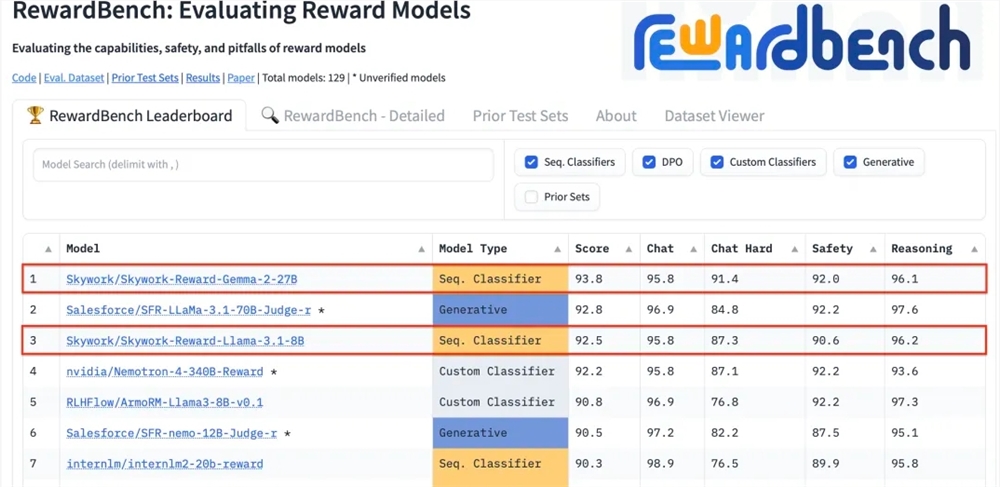
昆仑万维科技股份有限公司近日宣布,公司研发的两款全新奖励模型Skywork-Reward-Gemma-2-27B和Skywork-Reward-Llama-3.1-8B在国际权威的奖励模型评估基准RewardBench上表现卓越,其中Skywork-Reward-Gemma-2-27B模型更是荣获榜首,得到了RewardBench官方的高度认可。

Arcee AI 推出 SuperNova,一款针对企业部署的 700 亿参数大型语言模型,旨在提供强大、可拥有、注重数据隐私、模型稳定性和定制化的 AI 解决方案。SuperNova 采用 Meta 的 Llama-3.1-70B-Instruct 架构,并通过创新的后训练过程,具备先进指令遵循能力。它支持企业完全定制,并允许在企业自有云环境中部署,确保数据隐私和稳定性。与基于 API 的服务相比,SuperNova 提供了更灵活的控制和稳定性。此外,SuperNova 支持模型的微调和持续改进,允许根据企业需求进行个性化调整。Arcee 还发布了开源组件,包括免费 API、8B 参数的开源版本模型和数据集生成管道,以促进开发者社区的评估和定制。SuperNova 的性能在数学推理领域表现出色,并提供了对第三方评估的开放性,以验证其性能声明。此模型的发布反映了企业对 AI 解决方案控制和定制需求的增长,以及对数据隐私和模型稳定性的重视。

Nvidia研究团队利用模型剪枝和蒸馏技术,成功推出Llama-3.1-Minitron4B,这是Llama3模型的压缩版本,旨在实现设备上的人工智能。该模型通过深度剪枝和宽度剪枝技术,减少了原始8B模型的参数量,同时保持了与更大模型相近的性能。在训练数据量大幅减少(40倍)的情况下,该模型在MMLU基准测试中的性能提升了16%。该成果通过NVIDIA的NeMo-Aligner进行微调,适用于指令跟随、角色扮演、检索增强生成(RAG)和函数调用等任务。宽度剪枝版本已发布于Hugging Face平台,支持商业使用,为用户和开发者提供高效、性能卓越的模型选择。
Meta 在印度大选期间进行了几个月的测试后,决定将其 Llama-3技术驱动的 AI 聊天机器人推广到所有印度用户。然而,Meta AI 目前仅支持英文,不支持其他本地语言。
["开源 Mistral7B v0.2Base Model,上下文提升至 32K","与微软达成合作协议,微软投资 1600 万美元","发布旗舰级大模型 Mistral Large,直接竞争 GPT-4","持续发展,超越传统竞争对手,推出新模型"]
["Meta 发布两个 24K H100GPU 集群用于训练 Llama-3。","Llama-3 使用 RoCEv2 网络和 Tectonic/Hammerspace 的 NFS/FUSE 网络存储。","预计 Llama-3 将于 4 月末或 5 月中旬上线,可能是多模态模型且会继续开源。","Meta 计划到 2024 年底拥有 600,000 个 H100 的算力。"]