टर्बाइन
आपके AI अनुप्रयोगों को सपोर्ट करने के लिए ऑटोमेटेड डेटा पाइपलाइन
सामान्य उत्पादउत्पादकताऑटोमेटेड डेटा पाइपलाइनवेक्टर डेटाबेस
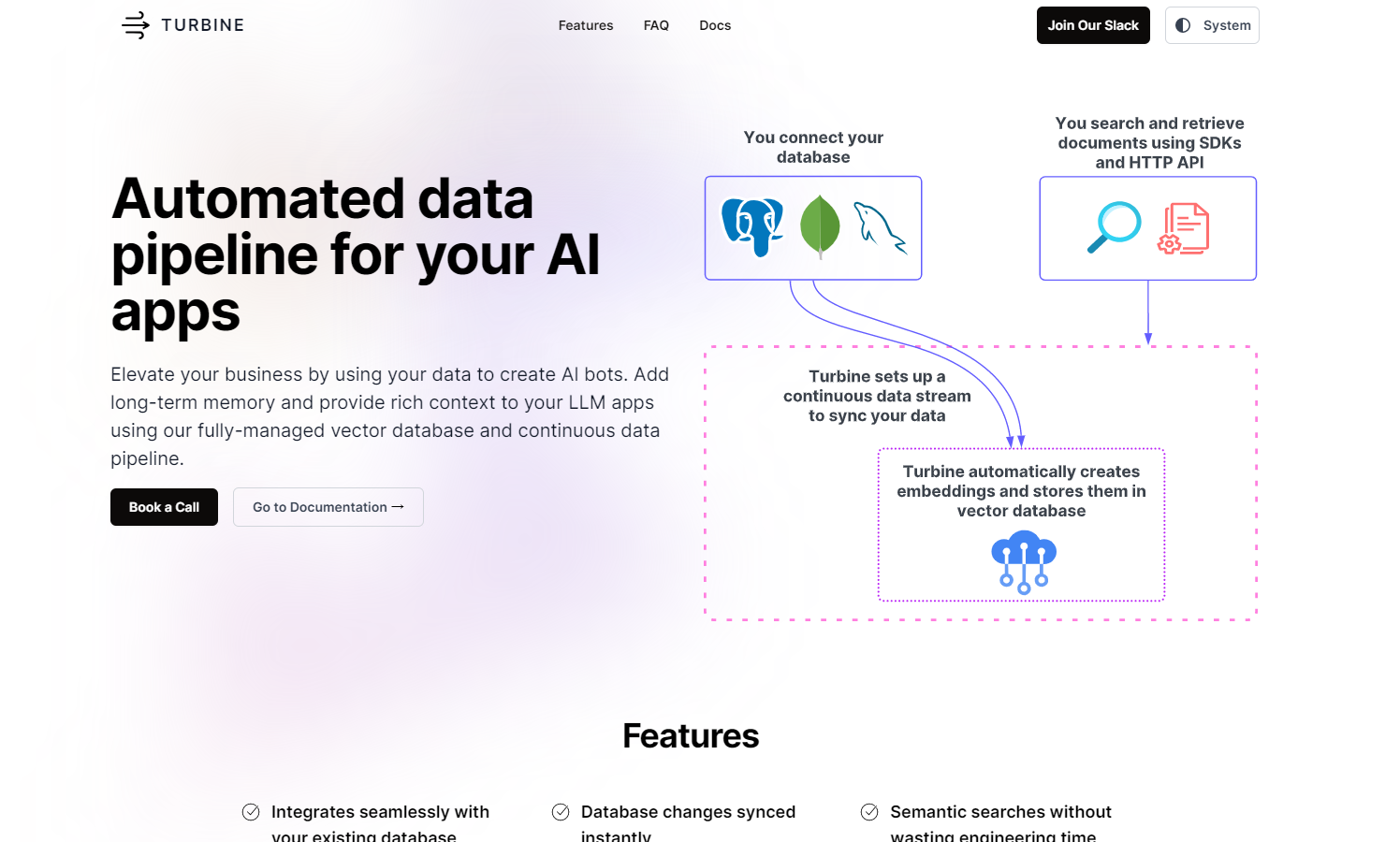
टर्बाइन एक ऑटोमेटेड डेटा पाइपलाइन टूल है जो आपके AI अनुप्रयोगों को सपोर्ट करता है। यह आपके LLM अनुप्रयोगों में दीर्घकालिक मेमोरी और संपूर्ण संदर्भ जोड़ने के लिए एक पूरी तरह से प्रबंधित वेक्टर डेटाबेस और निरंतर डेटा पाइपलाइन का उपयोग करता है। टर्बाइन आपके मौजूदा डेटाबेस के साथ सहज रूप से एकीकृत हो सकता है, PostgreSQL, MongoDB और MySQL डेटाबेस को सपोर्ट करता है। यह अत्याधुनिक डेटा इंजीनियरिंग पाइपलाइन का उपयोग करता है, वास्तविक समय में डेटाबेस परिवर्तनों को सिंक करता है, सिमेंटिक सर्च को सपोर्ट करता है, Pinecone और Milvus जैसे वेक्टर डेटाबेस को सपोर्ट करता है, कई एम्बेडिंग मॉडल को सपोर्ट करता है, Python और TypeScript SDKs के माध्यम से आसानी से लॉन्च किया जा सकता है, आपके उपयोग के मामले के अनुसार समायोजित और अनुकूलित किया जा सकता है, LangChain AI बॉट के साथ आसानी से एकीकृत किया जा सकता है, और अत्यंत तेज गति और स्केलेबिलिटी प्रदान करता है।