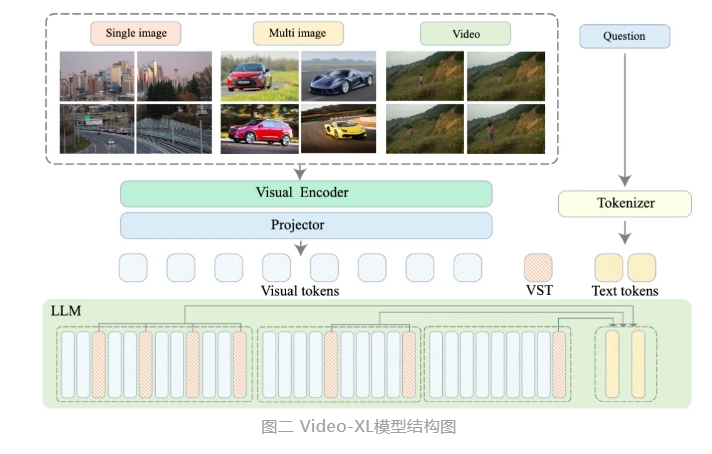
従来の動画理解モデルは、長尺動画の処理において、複雑なコンテキスト理解など多くの課題に直面していました。様々な研究で動画理解能力の向上を目指していますが、訓練と推論の効率の低さを効果的に克服するのは困難でした。これらの問題に対し、研究チームはHiCo技術を用いて動画情報の冗長部分を圧縮することで、計算需要を大幅に削減しつつ、重要な情報を保持することに成功しました。

具体的には、HiCoは動画を階層的に圧縮し、長尺動画を短いセグメントに分割することで、処理するトークンの数を削減します。この手法は、モデルの計算資源への要求を軽減するだけでなく、コンテキストウィンドウの幅を広げ、モデルの処理能力を向上させます。さらに、ユーザーのクエリとの意味的な関連性を利用することで、動画トークンの数をさらに削減しています。
長尺動画処理の具体的な実装において、「VideoChat-Flash」は、多段階の短尺動画から長尺動画への学習スキームを採用しています。研究者らはまず、短尺動画とその対応するアノテーションを用いて教師あり微調整を行い、その後、段階的に長尺動画を導入して訓練することで、混合長のコーパスに対する包括的な理解を実現しました。この手法は、モデルの視覚的認識能力を高めるだけでなく、長尺動画処理のための豊富なデータサポートを提供しており、研究チームは30万時間分の動画と2億語のアノテーションを含む巨大なデータセットを構築しました。
さらに、本研究では、マルチホップ動画設定のための改良された「干し草の山の中の針」タスクを提案しています。新しいベンチマークにより、モデルは動画内の単一ターゲット画像を見つけるだけでなく、複数の相互に関連する画像シーケンスを理解する必要があり、これによりモデルのコンテキスト理解能力が向上します。
実験結果は、提案手法が計算量を2桁削減し、特に短尺動画と長尺動画のベンチマークテストで優れた性能を示し、新たな短尺動画理解分野のリーダーとなっていることを示しています。同時に、このモデルは長尺動画理解においても既存のオープンソースモデルを凌駕し、強力な時間的局在化能力を示しています。
論文:https://arxiv.org/abs/2501.00574
要点:
🌟 研究者らは、階層的な動画トークン圧縮技術HiCoを提案し、長尺動画処理の計算需要を大幅に削減しました。
📹 「VideoChat-Flash」システムは、多段階学習手法を採用し、短尺動画と長尺動画を組み合わせて訓練することで、モデルの理解能力を向上させました。
🔍 実験結果は、この手法が複数のベンチマークテストで新たな性能基準を達成し、長尺動画処理分野の先進的なモデルとなっていることを示しています。