人工知能技術の急速な発展に伴い、様々な生成AIモデルの能力を効果的に評価・比較することが大きな課題となっています。従来のAIベンチマークテストは限界を示しつつあり、AI開発者たちはより革新的な評価方法の模索に励んでいます。
最近、「Minecraft Benchmark」(略称:MC-Bench)というウェブサイトが登場しました。そのユニークな点は、マイクロソフトのサンドボックス型建築ゲーム「マインクラフト」(Minecraft)をプラットフォームとして利用し、AIモデルがプロンプトに基づいて作成したゲーム作品を比較することで、モデルの性能を評価するという点です。驚くべきことに、この斬新なプラットフォームの開発者は、高校12年生の生徒なのです。

「マインクラフト」がAI競技場に
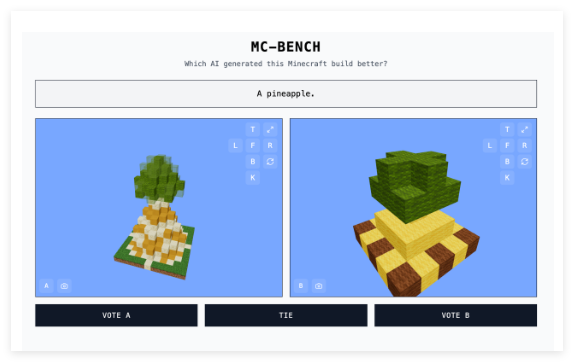
MC-Benchウェブサイトは、直感的で面白いAIモデル評価方法を提供しています。開発者たちは、テスト対象のAIモデルに様々なプロンプトを入力します。モデルはそれに応じて「マインクラフト」の建造物を生成します。ユーザーは、どの作品がどのAIモデルによって作成されたか分からない状態で、プロンプトに合致し、より優れた作品に投票します。投票終了後にのみ、各建造物の「制作者」が明かされます。この「ブラインドテスト」方式は、AIモデルの実際の生成能力をより客観的に反映することを目指しています。
Adi Singh氏は、「マインクラフト」をベンチマークテストのプラットフォームとして選択した理由について、ゲームの人気度(世界で最も売れたゲームの一つであること)だけではないと述べています。それ以上に、このゲームの普及度と視覚スタイルの親しみやすさにより、ゲームをプレイしたことがない人でも、どのブロックでできたパイナップルがよりリアルに見えるかを比較的容易に判断できるからです。「マインクラフト」は人々が[AIの発展]の進歩をより容易に理解できるようにする、と彼は考え、この視覚的な評価方法は、単純なテキスト指標よりも説得力があると述べています。
機能に焦点を当てる
MC-Benchは現在、主に「霜の王」や「原始的な砂浜にある魅力的なトロピカルハウス」といったプロンプトに基づいて、AIモデルがコードを記述し、対応するゲーム構造を作成する、比較的単純な建築タスクを実行しています。これは本質的にプログラミングベンチマークテストですが、巧妙な点は、ユーザーが複雑なコードを深く理解する必要がなく、直感的な視覚効果だけで作品の良い悪さを判断できるため、プロジェクトへの参加度とデータ収集の可能性が大幅に向上している点です。
MC-Benchの設計理念は、多くの人がAI技術の発展レベルをより直感的に理解できるようにすることです。「現在のランキングは、私がこれらのモデルを使用した経験と非常に合致しており、多くの純粋なテキストベンチマークテストとは異なります」とSingh氏は述べています。彼は、MC-Benchが関連企業にとって貴重な参考となり、自社のAI開発の方向性が正しいかどうかを判断するのに役立つ可能性があると考えています。
MC-BenchはAdi Singh氏によって開始されましたが、多くのボランティア貢献者も参加しています。注目すべきは、Anthropic、Google、OpenAI、アリババなど、多くのトップAI企業が、ベンチマークテストを実行するために製品の使用料を補助していることです。ただし、MC-Benchのウェブサイトでは、これらの企業はそれ以外の方法でこのプロジェクトに関与していないと明記されています。
Singh氏は、MC-Benchの将来についても展望を語っています。現在行われている単純な建築は始まりに過ぎず、将来的にはより長期的な計画や目標指向のタスクに拡大する可能性があると述べています。ゲームは、AIの「代理推論」能力を安全かつ制御された媒体でテストする手段となり得ると考えており、これは現実世界では実現が困難なため、テスト面でより有利であると述べています。
画期的なAI評価の新視点
MC-Bench以外にも、「ストリートファイター」や「ピクショナリ」などのゲームがAIの実験的なベンチマークテストに使用されたことがあり、AIベンチマークテスト自体が非常に高度な技術分野であることを示しています。従来の標準化された評価には、「ホームアドバンテージ」が存在することが多く、AIモデルはトレーニング中に特定の種類の問題に対して最適化されているため、特に暗記や基本的な推論が必要な問題では優れた成績を収めます。例えば、OpenAIのGPT-4はLSAT試験で88%という優秀な成績を収めましたが、「strawberry」という単語にいくつの「R」が含まれているかを判別することはできませんでした。

AnthropicのClaude3.7Sonnetは、標準化されたソフトウェアエンジニアリングベンチマークテストで62.3%の精度を達成しましたが、「ポケモン」のプレイに関しては、5歳児の多くよりも劣っていました。
MC-Benchの登場は、生成AIモデルの能力を評価する上で、新しく、より理解しやすい視点を与えてくれます。広く知られているゲームプラットフォームを利用することで、複雑なAI技術能力を直感的な視覚比較に変換し、より多くの人がAIの評価と認知プロセスに参加できるようになります。この評価方法の実質的な価値についてはまだ議論の余地がありますが、AIの発展を観察するための新しい窓を提供してくれることは間違いありません。