
この度、テンセントは独自開発の大規模言語モデル「混元T1」正式版を正式にリリースしました。
混元T1正式版は、大規模強化学習に基づき、数学、論理推論、科学、コードといった理系分野の難問に対して特化して最適化されており、推論能力の大幅な向上を実現しています。MMLU-PROなどの一般的なベンチマークにおいて、混元T1は87.2点という優れた成績を収め、トップモデルであるo1に次ぐ結果となりました。また、CEval、AIME、Zebra Logicなど、英語と中国語の知識、そして競争レベルの数学・論理推論に関する公開ベンチマークテストでも、業界をリードする推論モデルとしての水準を示しました。
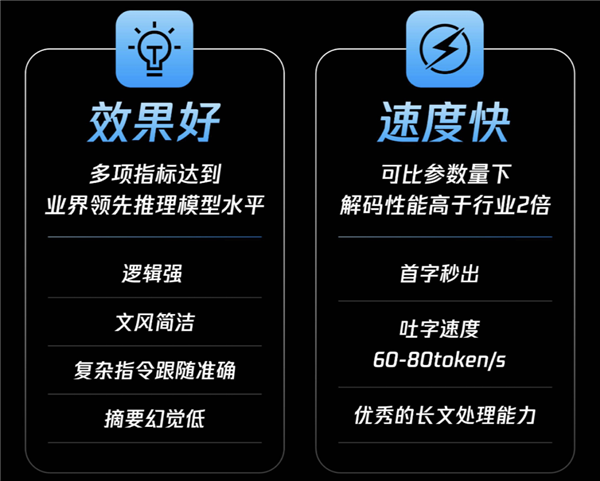
基本的な推論能力に加え、混元T1正式版は、複数の調整タスク、指示に従うタスク、ツールを利用するタスクにおいても非常に高い適応性を示しています。これは、混元Turbo Sの革新的なアーキテクチャを引き継ぎ、Hybrid-Mamba-Transformer融合モデルを採用していることによるものです。これは、業界で初めて混合Mambaアーキテクチャを大規模推論モデルに損失なく適用したものであり、従来のTransformer構造の計算複雑度を効果的に低減し、KV-Cacheのメモリ使用量を削減することで、トレーニングと推論のコストを大幅に削減しています。
さらに、優れた長文捕捉能力に基づき、混元T1は、長文推論においてよくあるコンテキストの欠落や長距離情報依存の問題を効果的に解決できます。混合Mambaアーキテクチャは長シーケンス処理向けに特化して最適化されており、効率的な計算方法により、長文情報の捕捉能力を確保しつつ、リソース消費を大幅に削減します。活性化パラメータ数がほぼ同じ条件下で、混元T1はデコード速度を2倍に向上させました。
現在、テンセント混元T1は体験版が公開されており、APIサービスも開始されています。ユーザーは必要に応じて、100万トークンあたり1元(入力)と100万トークンあたり4元(出力)の料金で、この強力な推論モデルがもたらす利便性と効率性を享受できます。



