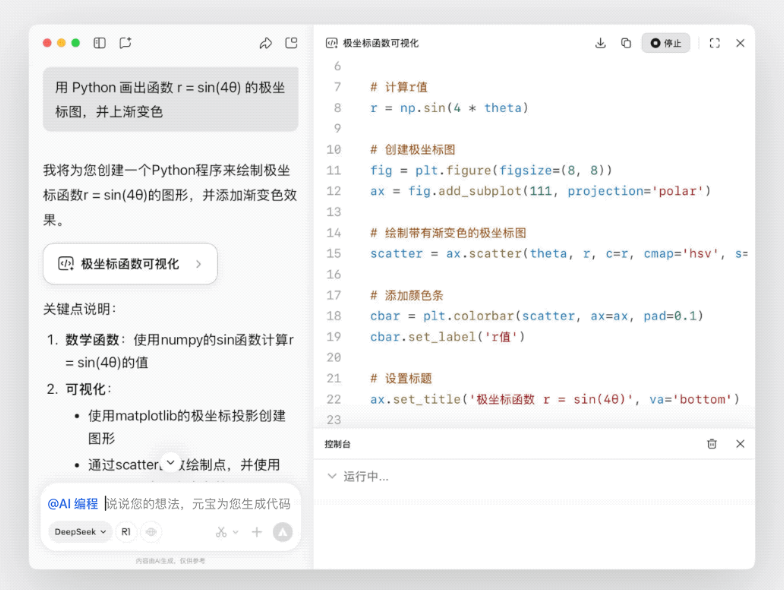
Recently, Microsoft's zero-shot text-to-speech (TTS) model, VALLE-2, has garnered widespread attention in the tech community. This groundbreaking achievement has for the first time achieved voice synthesis at a human parity level, marking a milestone in the TTS field.

Technical Highlights and Innovations:
Zero-shot learning: VALLE-2 only needs a brief sample of unfamiliar speech to mimic the same voice and speak any text content, demonstrating impressive instant mimicry capabilities.
Repetition-aware sampling: The improved random sampling method effectively alleviates the infinite loop problem and enhances decoding stability.
Grouped code modeling: By grouping the encoder-decoder codes, the sequence length is reduced, speeding up the inference process while improving performance.
Simplified training data requirements: VALLE-2 only requires simple voice-transcription text data for training, greatly simplifying the data collection and processing workflow.
Performance evaluation: On subjective scores (SMOS and CMOS) and objective metrics (SIM, WER, and DNSMOS), VALLE-2 not only surpasses its predecessor VALLE but also outperforms human speech in certain aspects.

Ethical Considerations and Market Reactions:
Potential risks: VALLE-2's powerful voice mimicry capabilities have raised concerns about the misuse of Deepfake technology.
Microsoft maintains a cautious stance, currently positioning VALLE-2 as a purely research project with no plans for commercialization. The company has included ethical statements on the project page and in the paper, emphasizing the necessity of synthetic voice detection and authorization mechanisms.
Some users expressed disappointment over Microsoft's decision not to release a trial product. Industry insiders speculate that Microsoft may be avoiding potential risks and negative public opinion. As the technology matures and market competition intensifies, the commercial application of VALLE-2 or similar technologies may only be a matter of time.
Technical Limitations and Improvement Areas:
Demo limitations: The publicly available demo samples are limited, making it difficult to fully assess the model's performance.
Accent adaptability: The model's effectiveness in handling non-Anglo-American accents needs improvement.
Computational efficiency: Although improvements have been made, there is still room for optimization in terms of inference speed.
The emergence of VALLE-2 signifies a new era for zero-shot TTS technology. It not only demonstrates the immense potential of AI in voice synthesis but also triggers deep thinking about the ethical and responsible use of technology. As the technology further develops and improves, we can expect to see more innovative applications. However, it also requires the joint efforts of the industry, regulatory bodies, and the public to ensure the responsible use of this powerful technology. In the future, VALLE-2 and similar technologies are likely to bring revolutionary changes to areas such as voice assistants, content creation, and education and training, while also driving advancements in voice recognition and synthesis detection technologies to address potential misuse risks.
Project Address: https://www.microsoft.com/en-us/research/project/vall-e-x/vall-e-2/