Recently, significant progress has been made in multi-modal large language models (MLLMs), particularly in the integration of visual and textual modalities. However, with the increasing prevalence of human-computer interaction, the importance of the speech modality has become more pronounced, especially in multi-modal dialogue systems. Speech is not only a key medium for information transmission but also significantly enhances the naturalness and convenience of interactions.

However, integrating visual and speech data into MLLMs is not an easy task due to the inherent differences between them. For instance, visual data conveys spatial information, while speech data communicates dynamic changes over time. These fundamental differences pose challenges for the synchronized optimization of the two modalities, often leading to conflicts during the training process. Furthermore, traditional speech-to-speech systems rely on separate automatic speech recognition (ASR) and text-to-speech (TTS) modules, which increases latency and reduces coherence, limiting their practicality in real-time applications.

To address these challenges, researchers have introduced VITA-1.5, a multi-modal large language model that integrates vision, language, and speech. VITA-1.5 employs a carefully designed three-stage training approach that gradually introduces visual and speech data to alleviate modality conflicts while maintaining strong multi-modal performance.
In the first stage, the model focuses on visual-language training by training a visual adapter and fine-tuning the model using descriptive captions and visual question-answering data to establish robust visual capabilities.
The second stage introduces audio input processing, training an audio encoder using speech transcription paired data, followed by fine-tuning with speech question-answering data, enabling the model to effectively understand and respond to audio inputs. Finally, in the third stage, the audio decoder is trained for end-to-end speech output without the need for an external TTS module, allowing VITA-1.5 to generate smooth speech responses, enhancing the naturalness and interactivity of multi-modal dialogue systems.
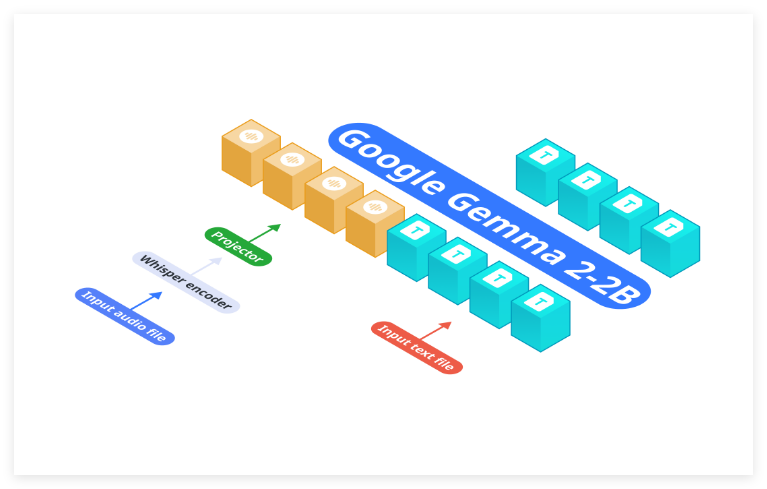
The overall architecture of VITA-1.5 includes visual and audio encoders along with adapters connected to a large language model. The output side features an end-to-end speech generation module, rather than using an external TTS model as in the original VITA-1.0 version. The visual encoder employs InternViT-300M, with input images sized at 448×448 pixels, generating 256 visual tokens per image.
For high-resolution images, VITA-1.5 utilizes a dynamic patching strategy to capture local details. Videos are treated as a special type of multi-image input, with frames sampled based on video length. The audio encoding module consists of multiple down-sampling convolutional layers and 24 Transformer blocks, producing an output frame rate of 12.5Hz. The audio adapter consists of several convolutional layers with 2x down-sampling. TiCodec is used as the codec model, encoding continuous speech signals into discrete speech tokens at a frequency of 40Hz and capable of decoding them back into speech signals at a sampling rate of 24,000Hz. To enable the model to output speech tokens, two speech decoders are added after the text tokens: a non-autoregressive (NAR) speech decoder and an autoregressive (AR) speech decoder.
The training data for VITA-1.5 covers a wide range of categories, including caption data and question-answering data in both Chinese and English. During different training stages, subsets of the entire dataset are selectively sampled to serve different objectives. The training strategy is divided into three phases:
Phase One: Visual-Language Training, including visual alignment, visual understanding, and visually supervised fine-tuning, aims to bridge the gap between vision and language, enabling the model to understand image content and answer visual questions.
Phase Two: Audio Input Fine-Tuning, including audio alignment and audio supervised fine-tuning, aims to enable the model to understand audio inputs and interact through speech questions and text answers.
Phase Three: Audio Output Fine-Tuning, including codec training and NAR + AR decoder training, aims to enable the model to generate speech output, achieving end-to-end speech interaction.
The researchers conducted extensive evaluations on various benchmarks for image, video, and speech understanding and compared the results with open-source and proprietary models. The results indicate that VITA-1.5 exhibits perceptual and reasoning capabilities comparable to leading MLLMs in image and video tasks and has made significant improvements in speech capabilities. For instance, in image understanding benchmarks, VITA-1.5's performance is on par with state-of-the-art open-source models and even surpasses some closed-source models. In video understanding, VITA-1.5 performs comparably to top open-source models. Additionally, VITA-1.5 has achieved leading accuracy in ASR tasks in both Chinese and English, surpassing specialized speech models.
Overall, VITA-1.5 successfully integrates vision and speech through a carefully designed three-stage training strategy, achieving strong visual and speech understanding capabilities, enabling efficient speech-to-speech interaction without relying on separate ASR or TTS modules. This research is expected to advance the progress of open-source models in the field of real-time multi-modal interaction.
Project Address: https://github.com/VITA-MLLM/VITA