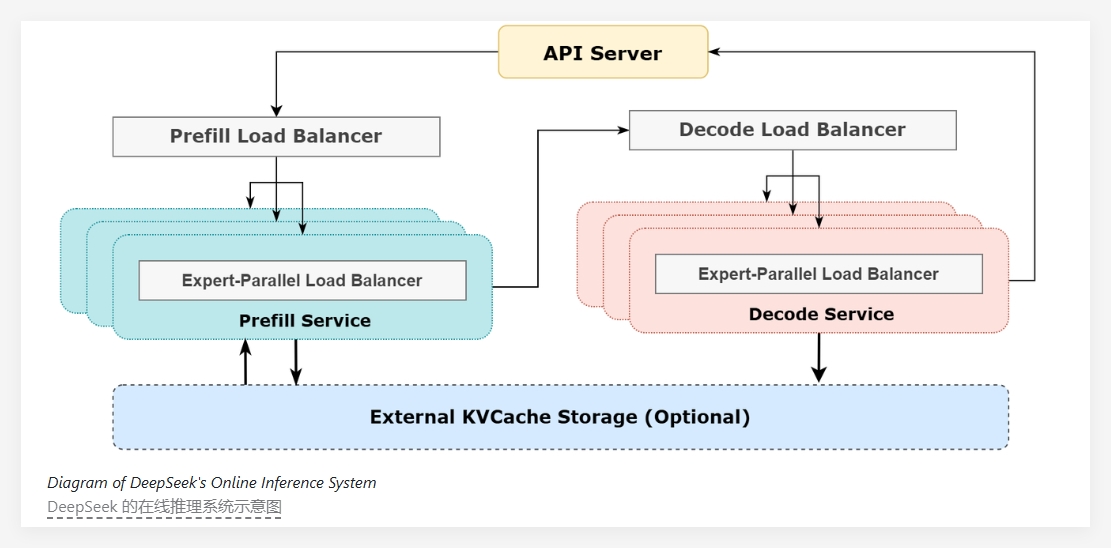
ByteDance recently announced the open-sourcing of its newly developed AIBrix inference system. This system is specifically designed for the vLLM inference engine, aiming to provide a scalable and cost-effective inference control plane to meet the growing AI demands of enterprises.
The launch of AIBrix marks a new phase. The project team hopes to lay the foundation for building scalable inference infrastructure through this open-source project. The system offers a complete cloud-native solution, focusing on optimizing the deployment, management, and scalability of large language models. It's particularly well-suited to enterprise-level needs, ensuring users enjoy more efficient service.

Functionally, the initial release of AIBrix focuses on several key features. First is high-density LoRA (Low-Rank Adaptation) management, designed to simplify lightweight model adaptation support, making model management easier for users. Second, AIBrix provides LLM gateway and routing capabilities, efficiently managing and distributing traffic across multiple models and replicas to ensure requests reach their target models quickly and accurately. Furthermore, an auto-scaler for LLM applications dynamically adjusts inference resources based on real-time demand, improving system flexibility and responsiveness.
ByteDance's AIBrix team stated that they plan to continue evolving and optimizing the system by expanding distributed KV caching, incorporating traditional resource management principles, and improving computational efficiency based on performance analysis.