In today's rapidly advancing artificial intelligence (AI) landscape, effectively evaluating and comparing the capabilities of different generative AI models has become a significant challenge. Traditional AI benchmark methods are increasingly showing their limitations, prompting AI developers to explore more innovative evaluation approaches.
Recently, a website called "Minecraft Benchmark" (MC-Bench) emerged, uniquely utilizing Microsoft's sandbox game, Minecraft, as its platform. Users compare AI-generated in-game creations based on prompts to assess model performance. Surprisingly, this innovative platform was created by a high school student.

Minecraft Transformed into an AI Arena
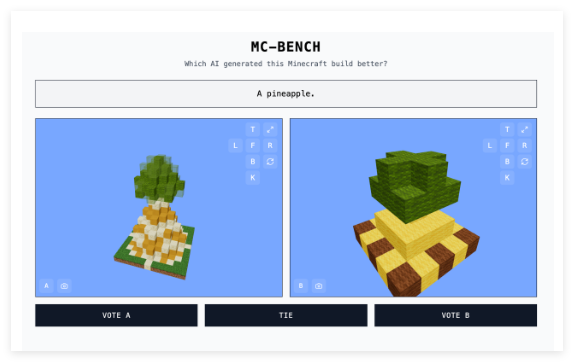
MC-Bench offers an intuitive and engaging way to evaluate AI models. Developers input various prompts into the participating AI models, which then generate corresponding Minecraft structures. Users vote on which structure best fits the prompt without knowing which AI model created it, selecting the superior creation. Only after voting do users see the creator of each building. This "blind selection" mechanism aims for a more objective reflection of the AI models' actual generative capabilities.
Adi Singh stated that choosing Minecraft wasn't solely due to its popularity—it's one of the best-selling video games of all time. More importantly, its widespread familiarity and visual style allow even non-players to easily judge which block-based pineapple looks more realistic. He believes Minecraft makes "progress [in AI development] easier to see," offering a more compelling visual assessment than purely textual metrics.
Focus on Functionality
MC-Bench currently focuses on relatively simple building tasks. For example, prompts like "Frost King" or "Charming tropical hut on a pristine beach" instruct AI models to write code creating the corresponding in-game structures. Essentially, it's a programming benchmark, but its cleverness lies in the intuitive visual judgment of quality, eliminating the need for complex code analysis and significantly increasing participation and data collection potential.
MC-Bench aims to make AI advancements more accessible to the public. "The current leaderboard aligns well with my personal experience using these models, unlike many purely text-based benchmarks," Singh noted. He believes MC-Bench could provide valuable insights for companies, helping them gauge the direction of their AI research.
While initiated by Adi Singh, MC-Bench has a team of volunteer contributors. Leading AI companies, including Anthropic, Google, OpenAI, and Alibaba, provide subsidized product usage for benchmark runs, although the website clarifies that these companies are not otherwise involved.
Singh envisions a future beyond simple building tasks, expanding to longer-term, goal-oriented missions. He suggests games could be a safe and controllable medium for testing AI's "agent reasoning" capabilities, surpassing the limitations of real-world testing.
A Groundbreaking New Approach to AI Evaluation
Beyond MC-Bench, games like Street Fighter and Pictionary have been used as experimental AI benchmarks, highlighting the nuanced nature of AI benchmark creation. Traditional standardized evaluations often exhibit a "home-field advantage," as AI models are trained to excel on specific problem types, particularly rote memorization or basic inference. For example, OpenAI's GPT-4 scored 88% on the LSAT but couldn't count the "R"s in "strawberry".

Anthropic's Claude 3.7 Sonnet achieved 62.3% accuracy on standardized software engineering benchmarks but underperformed most five-year-olds playing Pokémon.
MC-Bench offers a novel and more accessible perspective on evaluating generative AI models. By leveraging a widely known gaming platform, it translates complex AI capabilities into intuitive visual comparisons, enabling broader participation in AI evaluation and understanding. While its practical value is still under discussion, it undoubtedly provides a new window into observing AI development.