ImageBind
AI Multimodal Data Binding
CommonProductProductivityMultimodalImage
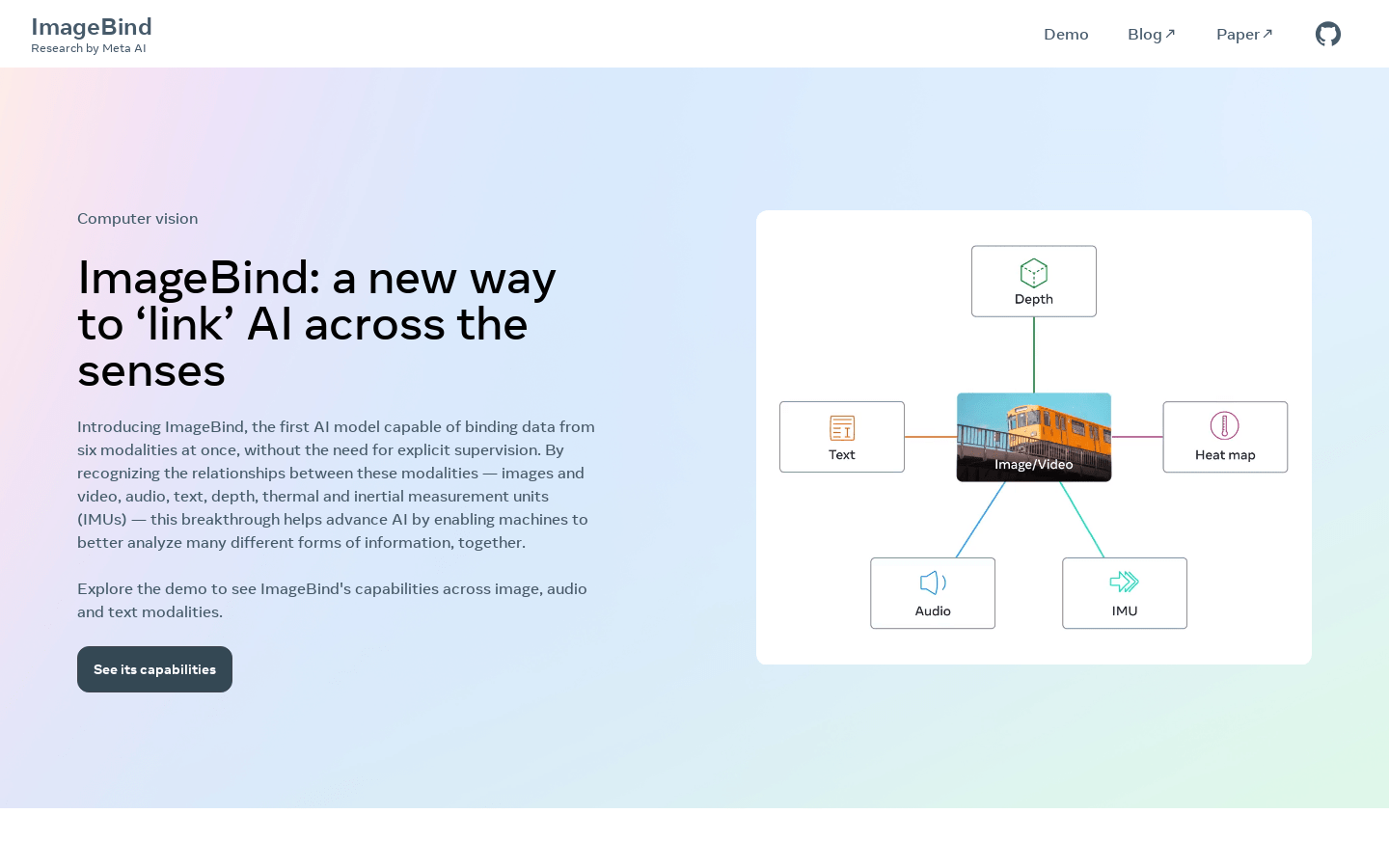
ImageBind is a new AI model that can bind data from six different sensory modalities simultaneously without explicit supervision. By recognizing the relationships between these modalities (images and videos, audio, text, depth, thermal imaging, and inertial measurement units (IMUs)), this breakthrough helps advance AI by enabling machines to better analyze various forms of information. Explore the demo to see ImageBind's capabilities across image, audio, and text modalities.
ImageBind Visit Over Time
Monthly Visits
1539
Bounce Rate
72.56%
Page per Visit
3.0
Visit Duration
00:00:12