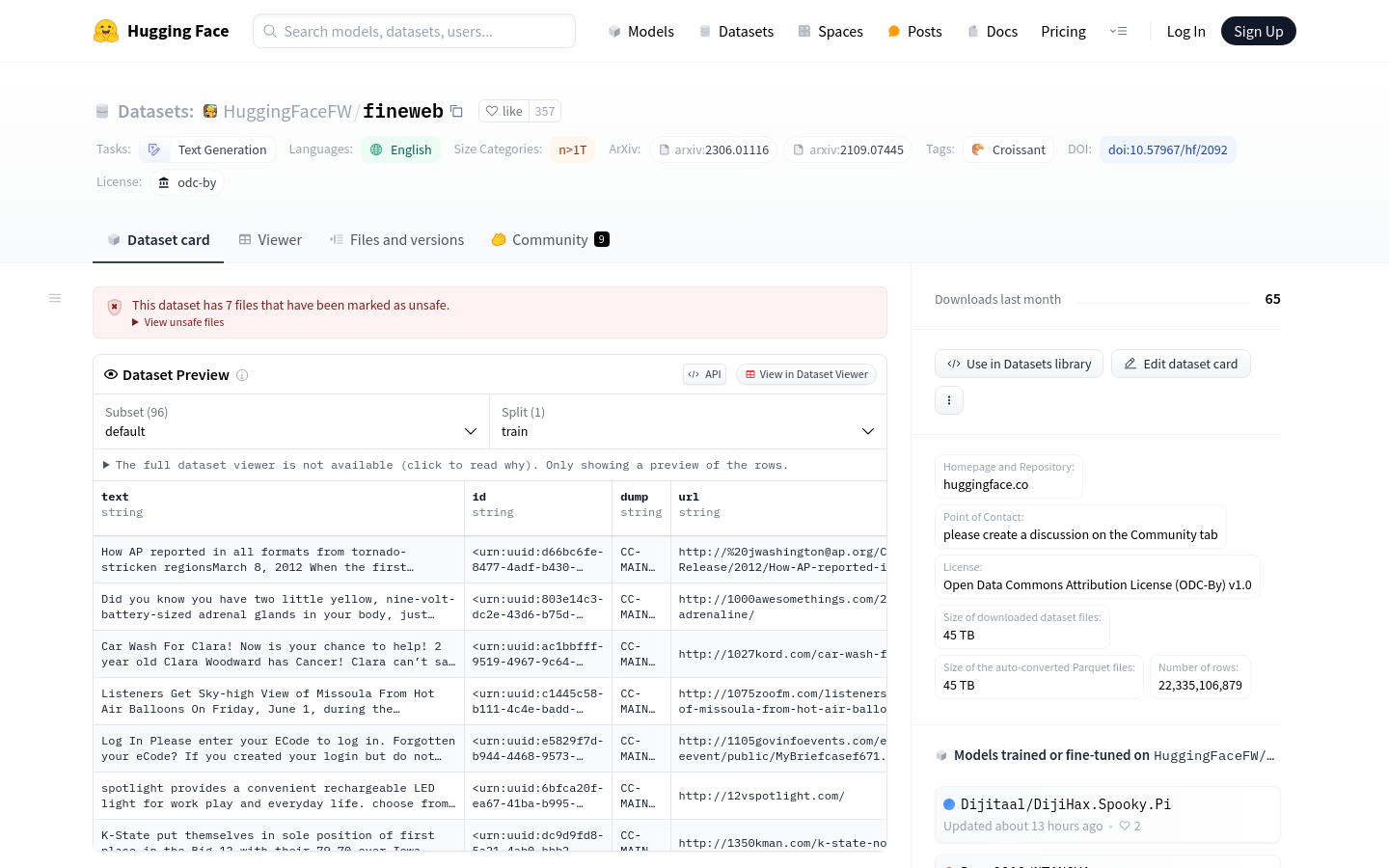
FineWeb
High-quality English webpage dataset
CommonProductProgrammingNatural Language ProcessingDataset
The FineWeb dataset contains over 150 billion web pages of cleaned and deduplicated English text sourced from CommonCrawl. Designed specifically for pre-training large language models, it aims to advance the development of open-source models. The dataset has been meticulously processed and filtered to ensure high quality, making it suitable for a variety of natural language processing tasks.
FineWeb Visit Over Time
Monthly Visits
27175375
Bounce Rate
44.30%
Page per Visit
5.8
Visit Duration
00:04:57