FineWeb
Conjunto de dados de páginas web em inglês de alta qualidade
Produto ComumProgramaçãoProcessamento de Linguagem NaturalConjunto de Dados
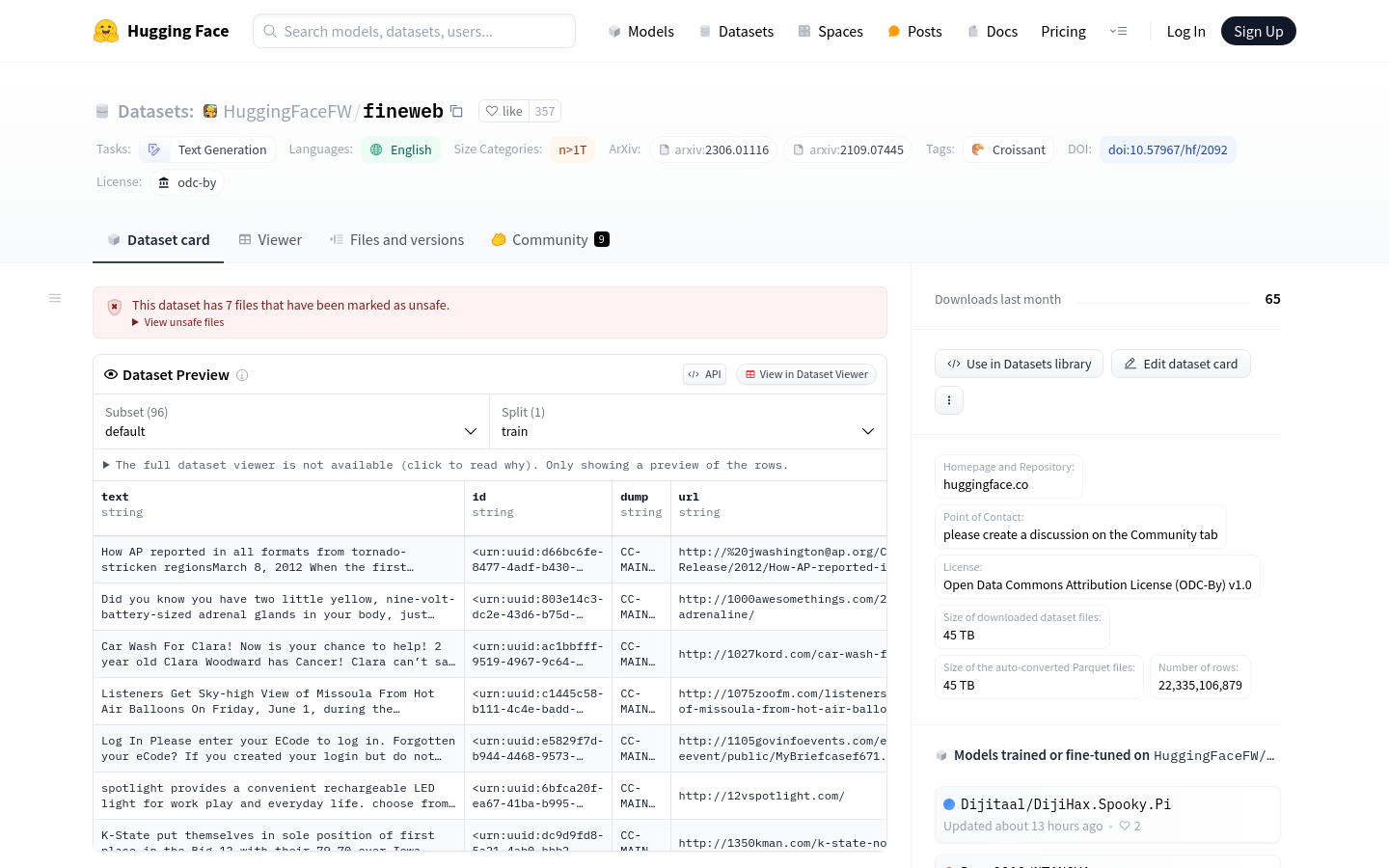
O conjunto de dados FineWeb contém mais de 15 trilhões de dados de páginas web em inglês, limpos e desduplicados, originários do CommonCrawl. Este conjunto de dados foi projetado especificamente para o pré-treinamento de modelos de linguagem de grande escala, com o objetivo de impulsionar o desenvolvimento de modelos de código aberto. Os dados foram cuidadosamente processados e filtrados para garantir alta qualidade e adequação a diversas tarefas de processamento de linguagem natural.
FineWeb Situação do Tráfego Mais Recente
Total de Visitas Mensais
27175375
Taxa de Rejeição
44.30%
Média de Páginas por Visita
5.8
Duração Média da Visita
00:04:57