在人工智能技术飞速发展的今天,如何有效地评估和比较不同生成式AI模型的实力,成为了一个备受关注的难题。传统的AI基准测试方法逐渐显露出其局限性,为此,AI开发者们正积极探索更具创新性的评估途径。
近日,一款名为“Minecraft Benchmark”(简称MC-Bench)的网站横空出世,其独特之处在于,它利用微软旗下的沙盒建造游戏《我的世界》(Minecraft)作为平台,让用户通过对比AI模型根据提示所创建的游戏作品,来评估它们的表现。而令人惊讶的是,这个新颖平台的创建者,竟然是一位年仅12年级的学生。

“我的世界”变身AI竞技场
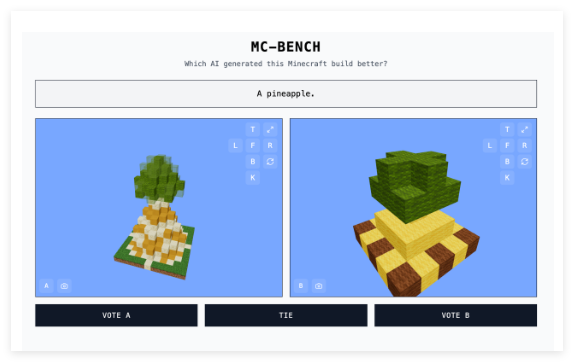
MC-Bench网站提供了一个直观有趣的AI模型评测方式。开发者们将不同的提示输入到参与测试的AI模型中,模型则会生成相应的《我的世界》建筑。用户可以在不清楚哪个作品由哪个AI模型创建的情况下,对这些建筑进行投票,选出他们认为更符合提示、更优秀的那个。只有在投票结束后,用户才能看到每个建筑背后的“创造者”。这种“盲选”机制旨在更客观地反映AI模型的实际生成能力。
Adi Singh表示,之所以选择《我的世界》作为基准测试的平台,并非仅仅因为游戏本身的受欢迎程度——它是史上最畅销的电子游戏。更重要的是,这款游戏的广泛普及性和人们对其视觉风格的熟悉度,使得即使是没有玩过这款游戏的人,也能够相对容易地判断出哪个由方块构成的菠萝看起来更逼真。他认为,“《我的世界》让人们更容易看到[AI发展]的进步”,这种可视化的评估方式比单纯的文本指标更具说服力。
功能聚焦
MC-Bench目前主要进行相对简单的建筑任务,例如根据“冰霜之王”或“在原始沙滩上的迷人热带小屋”这样的提示,让AI模型编写代码来创建相应的游戏结构。这本质上是一个编程基准测试,但其巧妙之处在于,用户无需深入研究复杂的代码,仅凭直观的视觉效果就能判断作品的优劣,这大大提高了项目的参与度和数据收集潜力。
MC-Bench的设计理念在于让大众能够更直观地感受到AI技术的发展水平。“目前的排行榜与我个人使用这些模型的体验非常吻合,这与许多纯文本基准测试不同,” Singh说道。他认为,MC-Bench或许能为相关公司提供一个有价值的参考,帮助他们判断自身AI研发的方向是否正确。
尽管MC-Bench由Adi Singh发起,但其背后也聚集了一批志愿贡献者。值得一提的是,包括Anthropic、谷歌、OpenAI和阿里巴巴在内的多家顶尖AI公司,都为该项目提供了使用其产品的补贴,以运行基准测试。不过,MC-Bench的网站声明这些公司并非以其他方式与该项目有关联。
对于MC-Bench的未来,Singh也充满了展望。他表示,目前进行的简单建筑只是一个起点,未来可能会扩展到更长期的计划和目标导向的任务。他认为,游戏可能成为测试AI“代理推理”能力的一种安全且可控的媒介,这在现实生活中难以实现,因此在测试方面更具优势。
开创性的AI评估新思路
除了MC-Bench之外,其他游戏如《街头霸王》和《你画我猜》也曾被用作AI的实验性基准测试,这反映出AI基准测试本身就是一个极具技巧性的领域。传统的标准化评估往往存在“主场优势”,因为AI模型在训练过程中已经针对某些特定类型的问题进行了优化,尤其是在需要死记硬背或基本推断的问题上表现出色。例如,OpenAI的GPT-4在LSAT考试中取得了88%的优秀成绩,却无法分辨单词“strawberry”中有多少个“R”。

Anthropic的Claude3.7Sonnet在标准化软件工程基准测试中达到了62.3%的准确率,但在玩《宝可梦》方面的表现却不如大多数五岁小孩。
MC-Bench的出现,为评估生成式AI模型的能力提供了一种新颖且更易于理解的视角。通过利用大众熟知的游戏平台,它将复杂的AI技术能力转化为直观的视觉对比,让更多人能够参与到AI的评估和认知过程中。虽然这种评估方式的实际价值仍在讨论之中,但无疑为我们提供了一个观察AI发展的新窗口。
项目入口:https://top.aibase.com/tool/mc-bench