
ロンドンのスタートアップ企業Stability AIは、潜在拡散技術を用いて最長90秒の高品質な商業音楽を生成できるAI音楽生成ツール「Stable Audio」を発表しました。
Stability AIは商業音楽ライブラリAudioSparxと提携し、Stable Audioに約80万曲の音楽を提供しています。ユーザーは様々なサブスクリプションプランを選択し、商業音楽を生成し、音楽ライブラリとの収益分配を行うことができます。
ロンドンのスタートアップ企業Stability AIは、潜在拡散技術を用いて最長90秒の高品質な商業音楽を生成できるAI音楽生成ツール「Stable Audio」を発表しました。
Stability AIは商業音楽ライブラリAudioSparxと提携し、Stable Audioに約80万曲の音楽を提供しています。ユーザーは様々なサブスクリプションプランを選択し、商業音楽を生成し、音楽ライブラリとの収益分配を行うことができます。

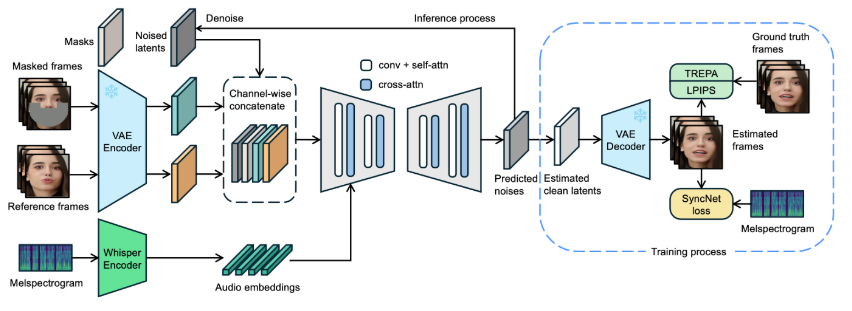
先日、バイトダンスは、オーディオ条件付き潜在拡散モデルを利用してより正確なリップシンクを実現することを目的とした、LatentSyncという新しいリップシンクフレームワークを発表しました。このフレームワークはStable Diffusionをベースに、時間的一貫性を最適化しています。従来のピクセル空間拡散や2段階生成の方法とは異なり、LatentSyncはエンドツーエンド方式を採用し、中間モーション表現を必要とせず、複雑なオーディオとビジュアル間の関係を直接モデル化できます。LatentSyncの

先日、阿里巴巴達摩院の研究チームは、重要な研究成果である「SHMT:自己教師あり階層的メイクアップ転移」を発表しました。この論文は、国際トップレベルの学術会議NeurIPS2024に採択されています。この研究は、潜在拡散モデル(Latent Diffusion Models)を利用して正確なメイクアップ画像生成を実現する、新しいメイクアップ効果転移技術を示しており、メイクアップアプリケーションと画像処理分野に新たな活力を注入しています。簡単に言うと、SHMTはメイクアップ転移技術であり、

Stability AIは最近、オープンソースのオーディオ生成モデル「Stable Audio Open」を発表しました。最大47秒間、サンプリングレート44.1kHzのステレオオーディオを生成できます。オープンウェイト設計を採用し、ユーザーはモデルの参照、修正、拡張が可能になり、研究開発とイノベーションを促進します。Creative Commonsライセンスのオーディオデータを使用してトレーニングされているため、データの合法性と倫理性が確保されています。高度なモデルアーキテクチャにより、高品質なステレオオーディオ生成が可能になり、多様性と高忠実度が実証されており、最先端モデルと同等の性能を発揮します。このツールは研究者にとって...