Make-It-Vivid
テキスト指示に従って、3Dテクスチャを持つカートゥーンキャラクターを自動生成・アニメーション化します。
一般製品画像3Dテクスチャ生成テキスト生成
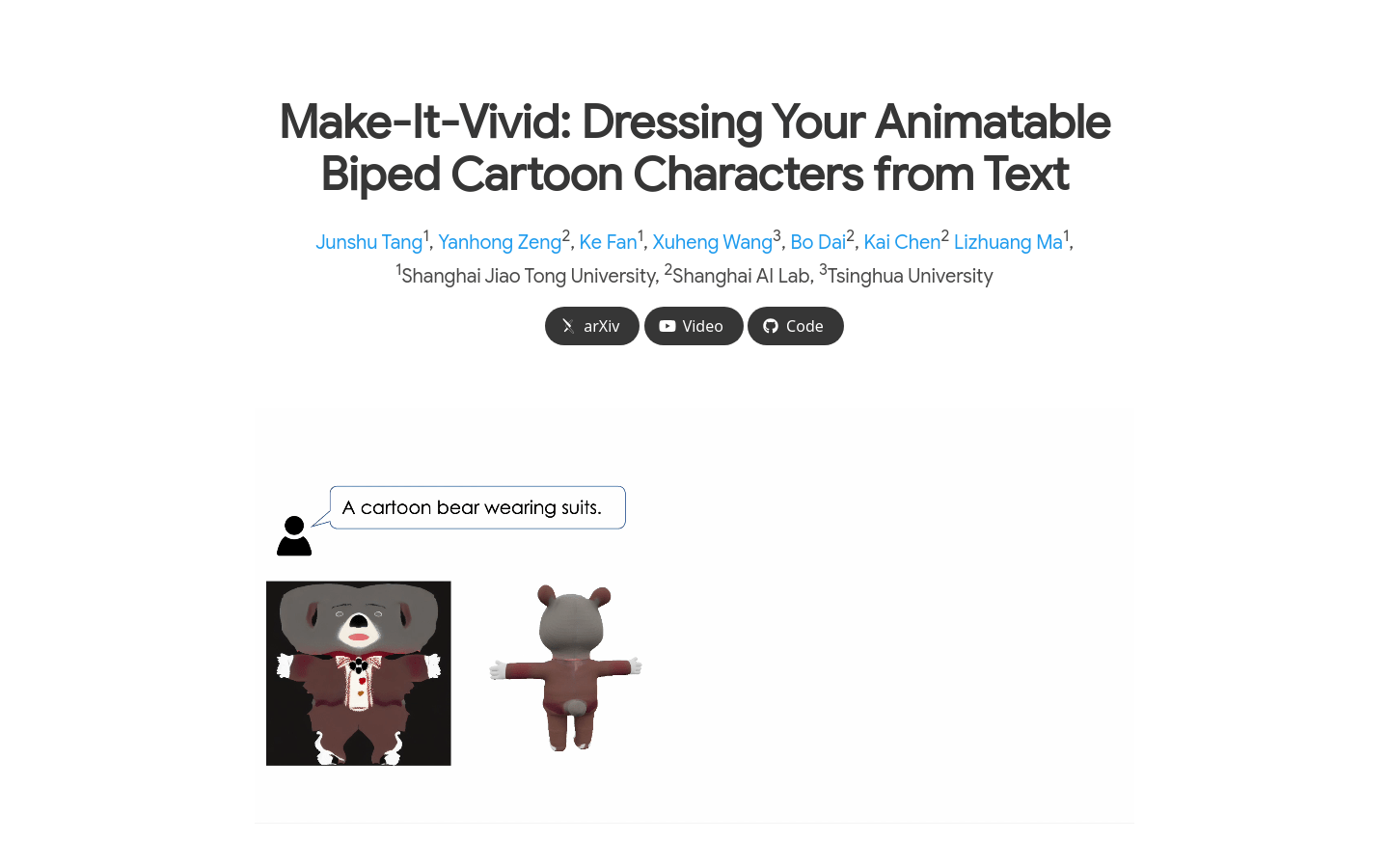
Make-It-Vividは、テキスト指示に基づき、3Dカートゥーンキャラクターのテクスチャを自動生成・アニメーション化する革新的なモデルです。従来の3Dカートゥーンキャラクターテクスチャ作成における課題を解決し、効率的で柔軟なソリューションを提供します。本モデルは、事前学習済みのテキストツーイメージ拡散モデルを用いて高品質なUVテクスチャマップを生成し、敵対的訓練を取り入れることでディテールの向上を実現しています。様々なテキストプロンプトに応じて多様なスタイルのキャラクターテクスチャを生成し、3Dモデルに適用してアニメーション制作を行うことができ、アニメーション制作、ゲーム開発等の分野に便利な創作ツールを提供します。