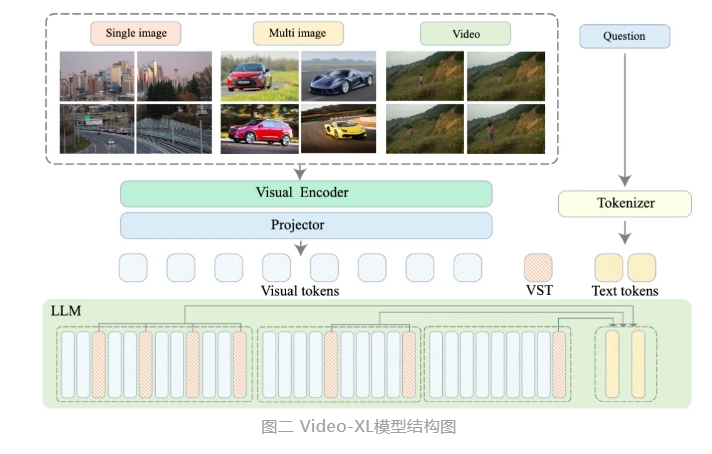
परंपरागत वीडियो समझ मॉडल लंबे वीडियो को संसाधित करते समय कई चुनौतियों का सामना करते हैं, जिसमें लंबे वीडियो द्वारा लाए गए जटिल संदर्भ को समझना शामिल है। हालांकि वीडियो समझ क्षमता को बढ़ाने के लिए कई शोध किए गए हैं, फिर भी प्रशिक्षण और अनुमान लगाने की दक्षता की कमी को प्रभावी ढंग से दूर करना कठिन है। इन समस्याओं के समाधान के लिए, शोध टीम ने HiCo तकनीक का उपयोग करके वीडियो जानकारी में मौजूद अतिरिक्त भागों को संकुचित किया, जिससे गणना की आवश्यकताओं को महत्वपूर्ण रूप से कम किया गया, जबकि महत्वपूर्ण जानकारी को बनाए रखा गया।

विशेष रूप से, HiCo वीडियो को स्तरित संकुचन के माध्यम से संसाधित करता है, लंबे वीडियो को छोटे खंडों में विभाजित करता है, जिससे संसाधित किए जाने वाले टैग की संख्या कम होती है। यह विधि न केवल मॉडल की गणना संसाधनों की आवश्यकता को कम करती है, बल्कि संदर्भ विंडो की चौड़ाई को भी बढ़ाती है, जिससे मॉडल की प्रसंस्करण क्षमता बढ़ती है। इसके अलावा, शोध टीम ने उपयोगकर्ता प्रश्नों के अर्थ संबंध का उपयोग करके वीडियो टैग की संख्या को और कम किया।
लंबे वीडियो के प्रसंस्करण के विशेष कार्यान्वयन में, "VideoChat-Flash" ने छोटे वीडियो से लंबे वीडियो की सीखने की योजना अपनाई। शोधकर्ताओं ने पहले छोटे वीडियो और उनके संबंधित टिप्पणियों का उपयोग करके पर्यवेक्षित सूक्ष्म समायोजन किया, फिर धीरे-धीरे लंबे वीडियो को प्रशिक्षण में शामिल किया, अंततः मिश्रित लंबाई सामग्री की समग्र समझ हासिल की। यह विधि न केवल मॉडल की दृश्य धारणा क्षमता को बढ़ाती है, बल्कि लंबे वीडियो के प्रसंस्करण के लिए समृद्ध डेटा समर्थन भी प्रदान करती है, शोध टीम ने 300,000 घंटे के वीडियो और 2 करोड़ शब्दों की टिप्पणियों के साथ एक विशाल डेटा सेट बनाया।
इसके अलावा, शोध में एक सुधारित "干草堆中的针" कार्य प्रस्तुत किया गया है, जो बहु-कूद वीडियो सेटिंग के लिए है। नए मानक के माध्यम से, मॉडल को वीडियो में एकल लक्ष्य छवि खोजने की आवश्यकता होती है, बल्कि कई आपस में जुड़े छवि अनुक्रमों को भी समझना होता है, जिससे मॉडल की संदर्भ समझने की क्षमता बढ़ती है।
प्रयोगात्मक परिणाम बताते हैं कि प्रस्तुत विधि ने गणना में दो गुणा कमी की है, विशेष रूप से छोटे और लंबे वीडियो के मानक परीक्षणों में उत्कृष्ट प्रदर्शन करते हुए, नए छोटे वीडियो समझ क्षेत्र का नेता बन गया है। साथ ही, यह मॉडल लंबे वीडियो समझने में भी मौजूदा ओपन-सोर्स मॉडल को पार कर गया, जो समय स्थान निर्धारण की मजबूत क्षमता को दर्शाता है।
पेपर: https://arxiv.org/abs/2501.00574
मुख्य बिंदु:
🌟 शोधकर्ताओं ने स्तरित वीडियो टैग संकुचन तकनीक HiCo प्रस्तुत की, जो लंबे वीडियो प्रसंस्करण की गणना आवश्यकताओं को महत्वपूर्ण रूप से कम करती है।
📹 "VideoChat-Flash" प्रणाली ने छोटे वीडियो और लंबे वीडियो को प्रशिक्षण में शामिल करने के लिए बहु-चरणीय सीखने की विधि अपनाई, जिससे मॉडल की समझने की क्षमता बढ़ी।
🔍 प्रयोगात्मक परिणाम दर्शाते हैं कि इस विधि ने कई मानक परीक्षणों में नए प्रदर्शन मानकों को हासिल किया, जिससे यह लंबे वीडियो प्रसंस्करण क्षेत्र का उन्नत मॉडल बन गया।