階躍星辰科技チームは、最新のマルチモーダル推論モデル「Step-R1-V-Mini」の正式リリースを発表しました。このモデルの発表は、マルチモーダル協調推論分野における新たなブレークスルーを意味し、AI技術の更なる発展に新たな活力を注ぎ込みます。Step-R1-V-Miniは画像とテキストの入力をサポートし、テキスト出力が可能です。指示に従う能力と汎用性に優れ、画像を高精度に認識し、複雑な推論タスクをこなせます。
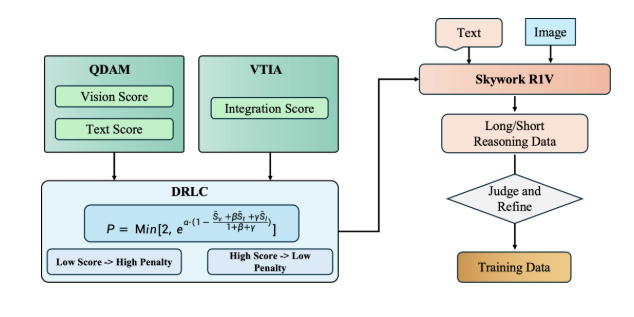
Step-R1-V-Miniのトレーニング方法は技術的に革新的で、マルチモーダル連合強化学習を採用しています。PPO(Proximal Policy Optimization)強化学習戦略に基づき、画像空間には検証可能な報酬メカニズムが導入されています。このメカニズムは、画像空間における推論経路の複雑さ、関連性や因果関係の推論における混同エラー発生の問題を効果的に解決します。DPO(Direct Preference Optimization)などの手法と比較して、Step-R1-V-Miniは画像空間の複雑な経路処理において、より優れた汎化性能と堅牢性を備えています。

さらに、マルチモーダル合成データを最大限に活用するために、階躍星辰は環境フィードバックに基づいた多数のマルチモーダルデータ合成経路を設計し、スケーラブルなトレーニングが可能なマルチモーダル推論データを作成しました。PPOベースの強化学習によるトレーニングを通じて、モデルのテキストと視覚推論能力を同時に向上させ、トレーニング過程におけるシーソー現象を効果的に回避しています。
視覚推論分野におけるパフォーマンスでは、Step-R1-V-Miniは顕著な成果を上げています。複数の公開ランキングでStep-R1-V-Miniは優れた成績を収め、特にMathVision視覚推論ランキングでは国内1位にランクインしました。これは、このモデルが視覚推論、数学的論理、コードなどにおいて優れた性能を持っていることを示しています。
Step-R1-V-Miniの実用例もその強力な機能を示しています。「画像から場所を特定する」ケースでは、ユーザーが撮影したウェンブリースタジアムの画像を入力すると、Step-R1-V-Miniは画像内の要素を迅速に認識し、色、物体(スタジアム、マンチェスターシティのエンブレムなど)といった異なる要素を組み合わせ、総合的に判断することで、場所をウェンブリースタジアムと正確に推定し、対戦チームの可能性も提示します。「画像からレシピを特定する」ケースでは、料理の写真を入力すると、Step-R1-V-Miniは料理とソースを正確に識別し、「新鮮なエビ300g、長ネギ白2本」など、具体的な分量を詳細にリストアップします。「物体の数の計算」ケースでは、形状、色、位置が異なる物体が配置された画像を入力すると、Step-R1-V-Miniは一つずつ識別し、物体の色、形状、位置に基づいて推論計算を行い、最終的に残りの物体の数を算出します。
Step-R1-V-Miniの発表は、マルチモーダル推論分野に新たな希望をもたらしました。このモデルは階躍AIウェブエンドで正式に公開されており、階躍星辰オープンソースプラットフォームでAPIインターフェースを提供し、開発者や研究者が体験・利用できます。階躍星辰は、Step-R1-V-Miniがマルチモーダル推論分野における段階的な成果であり、今後も推論モデルの分野で研究を続け、AI技術の更なる発展を推進すると述べています。
階躍AI ウェブエンド:
https://yuewen.cn/chats/new
階躍星辰オープンソースプラットフォーム:
https://platform.stepfun.com/docs/llm/reasoning