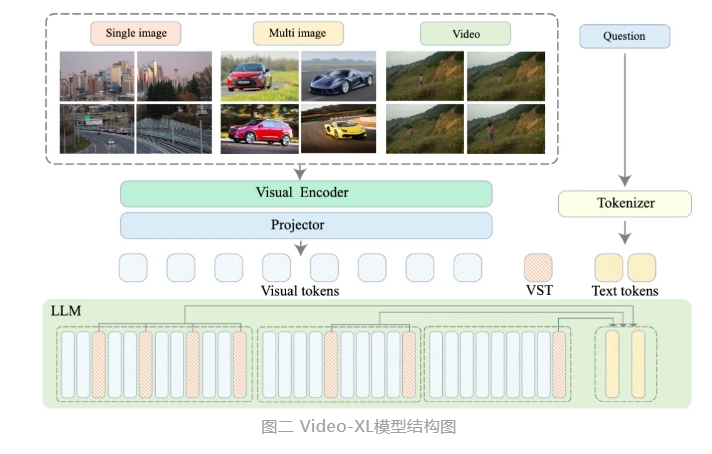
传统的视频理解模型在处理长视频时面临着许多挑战,包括理解长视频所带来的复杂上下文。尽管已有不少研究致力于提升视频理解能力,依然难以有效克服训练和推理效率低下的问题。针对这些问题,研究团队通过 HiCo 技术,将视频信息中的冗余部分进行压缩,从而显著降低计算需求,同时保留关键信息。

具体而言,HiCo 通过对视频进行层次化压缩,将长视频分割成短片段,进而减少处理的标记数量。这一方法不仅降低了模型对计算资源的要求,还提升了上下文窗口的宽度,增强了模型的处理能力。此外,研究团队还利用了与用户查询的语义关联,以进一步减少视频标记的数量。
在长视频处理的具体实现中,“VideoChat-Flash” 采用了一种多阶段的短视频到长视频的学习方案。研究人员首先使用短视频及其对应的注释进行监督微调,随后逐步引入长视频进行训练,最终实现了对混合长度语料的全面理解。这种方式不仅提高了模型的视觉感知能力,还为长视频的处理提供了丰富的数据支持,研究团队构建了一个包含300,000小时视频和2亿字注释的庞大数据集。
此外,研究中还提出了一种改进的 “干草堆中的针” 任务,用于多跳视频配置。通过新的基准,模型不仅需要找到视频中的单一目标图像,还需理解多个相互关联的图像序列,从而提高了模型对上下文的理解能力。
实验结果表明,所提出的方法在计算上减少了两个数量级,特别是在短视频和长视频的基准测试中表现出色,成为新的短视频理解领域的领导者。同时,该模型在长视频理解方面也超越了现有的开源模型,显示出强大的时间定位能力。
论文:https://arxiv.org/abs/2501.00574
划重点:
🌟 研究人员提出了层次化视频标记压缩技术 HiCo,显著降低长视频处理的计算需求。
📹 “VideoChat-Flash” 系统采用多阶段学习方法,结合短视频和长视频进行训练,提升了模型的理解能力。
🔍 实验结果显示,该方法在多个基准测试中达到了新的性能标准,成为长视频处理领域的先进模型。