今日,阶跃星辰与吉利汽车集团宣布,联合开源两款阶跃Step系列多模态大模型——Step-Video-T2V视频生成模型和Step-Audio语音模型。
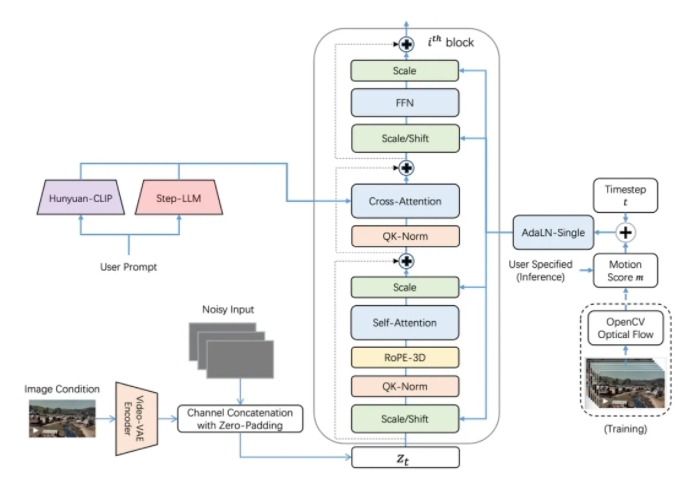
其中,阶跃Step-Video-T2V视频生成模型在参数量和性能上均处于全球领先水平。该模型拥有300亿参数量,能够直接生成204帧、540P分辨率的高质量视频,确保生成内容信息密度高、一致性强。评测结果显示,Step-Video-T2V在指令遵循、运动平滑性、物理合理性、美感度等方面均表现出色,显著超越市面上既有的最佳开源视频模型。

目前,这两款模型均已在跃问App内上线,供开发者朋友们体验并提供宝贵建议。
阶跃Step-Video-T2V视频生成模型在复杂运动、美感人物、视觉想象力等方面展现出卓越的生成能力。它能够精准理解指令,高效助力视频创作者实现创意呈现。无论是高雅优美的芭蕾舞、对抗激烈的空手道,还是紧张刺激的羽毛球、高速翻转的跳水,Step-Video-T2V都能生成真实且符合物理规律的画面。
同时,它还支持多种镜头运动方式和景别切换,能够生成大幅度运镜的视觉效果。生成的人物形象则更加逼真、生动,细节丰富,表情自然。
GitHub:
https://github.com/stepfun-ai/Step-Audio
Hugging Face:
https://huggingface.co/collections/stepfun-ai/step-audio-67b33accf45735bb21131b0b
技术报告:
https://github.com/stepfun-ai/Step-Audio/blob/main/assets/Step-Audio.pdf