
2025-03-12 15:28:43.AIbase.
El modelo de lenguaje grande de Ant Group para la atención médica obtiene el primer lugar en la evaluación de MedBench, marcando una nueva era para la IA médica

2025-02-26 09:56:15.AIbase.
El 92% de los estudiantes universitarios británicos dependen de la IA para sus tareas, ¡los sistemas de evaluación universitaria se enfrentan a un nuevo desafío!

2025-02-18 16:55:26.AIbase.
OpenAI lanza el benchmark SWE-Lancer: evaluación del rendimiento de los modelos en trabajos de ingeniería de software freelance reales

2025-01-10 15:49:29.AIbase.
El modelo GLM-4-9B de Zhihu logra una tasa de alucinación de solo el 1.3%, liderando la evaluación mundial de modelos de lenguaje grandes

2025-01-02 14:30:40.AIbase.
¿Microsoft revela accidentalmente los parámetros del modelo OpenAI en un nuevo artículo? Una evaluación de IA médica expone que 4o-mini solo tiene 8B

2024-12-26 10:54:51.AIbase.
El modelo Star grande de China Telecom seleccionado para la evaluación anual de "artefactos nacionales", creando un nuevo estándar para la IA nacional

2024-12-19 17:47:00.AIbase.
Plataforma de evaluación de modelos grandes CompassArena actualizada: nueva función Judge Copilot

2024-12-05 14:45:53.AIbase.
ByteDance lanza el nuevo benchmark de evaluación de modelos de código de fuente abierta "FullStack Bench"

2024-10-15 16:28:44.AIbase.
Informe de evaluación tecnológica de PDFtoChat: Sistema de preguntas y respuestas de PDF inteligente basado en IA
2024-10-12 11:38:17.AIbase.
OpenAI lanza MLE-bench: un conjunto de evaluación para agentes de IA

2024-10-10 11:00:51.AIbase.
Nuevo estándar de seguridad para vehículos: China lanza su primer sistema de evaluación de seguridad inteligente para automóviles

2024-09-29 15:33:05.AIbase.
Salesforce AI lanza la familia de modelos de evaluación de lenguaje grande SFR-Judge, basada en Llama 3

2024-09-03 13:42:26.AIbase.
DingTalk lanza varias "súper asistentes", incluyendo asistente de órdenes de trabajo súper y asistente de evaluación súper

2024-08-23 09:05:19.AIbase.
Baidu Smart Cloud Keyue pasa la evaluación del Instituto de Tecnología de las Telecomunicaciones de China sobre "Servicio de atención al cliente inteligente basado en modelos grandes"

2024-08-16 09:50:38.AIbase.
Geekbench lanza herramienta de prueba de rendimiento de IA: un nuevo estándar para la evaluación de la capacidad de IA de los dispositivos

2024-08-15 14:53:25.AIbase.
OpenAI lanza SWE-bench Verified: Mejora la evaluación de la capacidad de ingeniería de software de la IA
2024-08-13 08:11:01.AIbase.
Compass Arena, plataforma de evaluación de modelos grandes, añade una sección de competición para modelos multimodales

2024-07-23 08:09:28.AIbase.
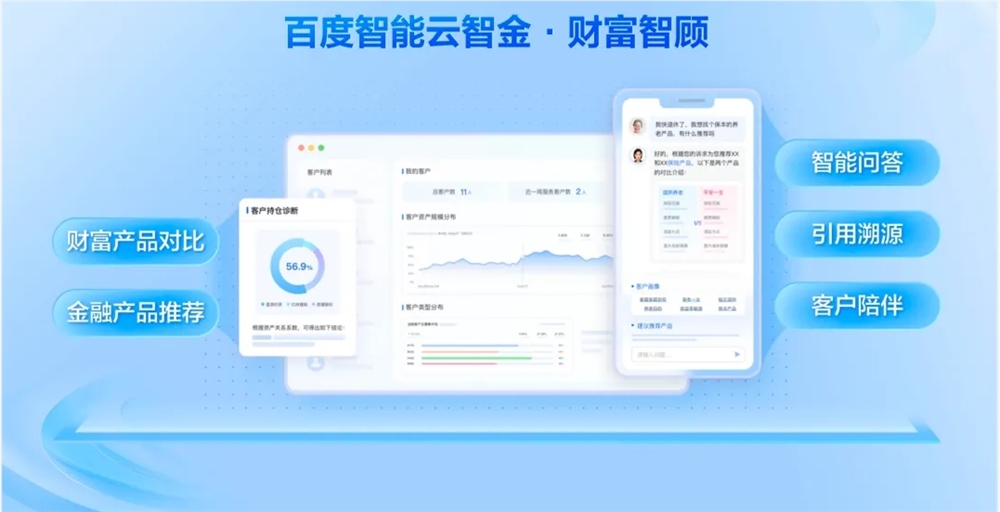
百度智能云 lanza la aplicación de entidad inteligente financiera "智金" con funciones de evaluación inteligente de activos
2024-07-12 11:10:22.AIbase.
OpenAI revela por primera vez sus estándares de evaluación para AGI: ChatGPT solo está en el primer nivel

2024-07-10 08:39:22.AIbase.