语音交互领域迎来里程碑式突破!国内AI公司阶跃(Step Audio)近日震撼开源了一款


语音交互领域迎来里程碑式突破!国内AI公司阶跃(Step Audio)近日震撼开源了一款
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
近日,复旦大学与国内AI创新企业阶跃星辰宣布即将推出一款名为OmniSVG的端到端多模态SVG生成模型,这一消息迅速引发了科技与设计领域的广泛关注。据AIbase了解,OmniSVG以其强大的生成能力为核心,支持从简单图标到复杂动漫角色的矢量图生成,为数字艺术创作提供了全新的智能解决方案。这一模型的问世,或将重新定义矢量图生成的技术边界。多模态生成:灵活应对多样需求OmniSVG的最大亮点在于其支持三种生成模式:通过文字描述生成SVG图像、将图片转化为矢量图,以及基于角色参考生成

欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、阿里巴巴已宣布全面支持MCP协议腾讯紧随其后近日,中国人工智能领域迎来技术标准的变革,ModelContextProtocol成为国内AI生态的事实标准。根据国家互联网信息办公室的要求,网信部门与相关单位共同推进生成式人工智能服务的备案工作,以促进这一领域的创新和规范应用。

阶跃星辰科技团队宣布正式推出全新的多模态推理模型 Step-R1-V-Mini。这一模型的发布标志着在多模态协同推理领域的新突破,为AI技术的进一步发展注入了新的活力。Step-R1-V-Mini支持图文输入和文字输出,具备良好的指令遵循能力和通用性,能够高精度感知图像并完成复杂的推理任务。

宝马集团与阿里巴巴集团正式宣布在中国市场达成一项重要的战略合作,双方将共同聚焦于人工智能(AI)大语言模型以及智能语音交互等前沿技术领域,致力于开发更符合中国用户需求的前沿解决方案。

欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、最贵!用户可以通过窗口前端的图标直接调用Gemini助手,享受自定义快捷键和系统托盘图标的支持,尽管目前不支持侧边栏固定模式。
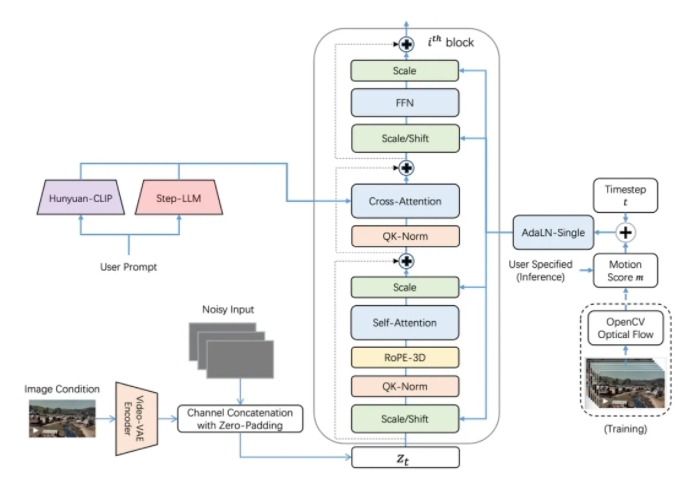
上海阶跃星辰智能科技有限公司宣布开源其最新的图生视频模型——Step-Video-TI2V。这一模型是基于30B参数的Step-Video-T2V训练而成,能够生成102帧、5秒、540P分辨率的视频,具有运动幅度可控和镜头运动可控两大核心特点,尤其在动漫效果方面表现出色。

就在各家AI大模型竞相迭代之际,一家备受瞩目的人工智能初创公司Anthropic正悄然酝酿着一项重大升级——为旗下AI聊天机器人Claude赋予“说话”的能力。Anthropic首席产品官迈克・克里格(Mike Krieger)近日向英国《金融时报》透露,公司正积极探索一系列全新的用户体验,让用户能够直接通过语音与强大的Claude AI模型进行交流。克里格指出,随着Claude的应用场景不断拓展,尤其是在桌面端,语音交互有望成为一种更加自然和高效的用户界面。“我们正在深入研究桌面端的Claude如何进一步发展

上海阶跃星辰智能科技有限公司与智元机器人正式签署深度战略合作协议,双方将在基座大模型和机器人研发领域展开深度合作,共同探索“大模型+具身机器人”的技术突破与应用创新。此次合作涉及世界模型技术研发、具身智能领域数据合作以及新零售等应用场景的落地,旨在推动具身智能技术在家庭服务、新零售、智能制造等领域的规模化应用。

在人工智能的激烈竞争中,一场耗资百万美元的大规模实验正悄然改变着大语言模型的训练方式。阶跃星辰研究团队日前发布重磅研究成果,他们通过耗费近100万NVIDIA H800GPU小时的算力,从零开始训练了3,700个不同规模的模型,累计训练了惊人的100万亿个token,揭示出一条被称为"Step Law"的普适性缩放规律,为大语言模型的高效训练提供了全新指南。这项研究不仅仅是对超参数优化的探索,更是第一个全面考察模型最优超参在不同形状、稀疏度和数据分布下稳定性的工作。研究结果表明,无

近日,魔乐社区(Modelers)正式上线了由阶跃星辰研发的 Step-Video 和 Step-Audio 两款开源多模态大模型。这两款模型分别用于视频生成和语音交互,旨在为开发者和企业用户提供更强大的 AI 工具。Step-Video 模型的全名为 Step-Video-T2V,这是一款参数量高达300亿的全球最大开源视频生成模型。该模型能够直接生成204帧、540P 分辨率的高质量视频,并在指令遵循、运动平滑性、物理合理性以及美感等方面,表现超越了市场上现有的顶尖开源视频模型。另一方面,Step-Audio 则是业内首款能够生成多种情