相关AI新闻推荐

社交新宠!Ghiblio.art一键实现吉卜力风格转换
Ghiblio.art是一个专注于将照片转化为吉卜力风格艺术作品的在线AI工具。吉卜力工作室(Studio Ghibli)以其手绘风格、柔和色调和充满奇幻氛围的场景闻名,如《千与千寻》《龙猫》等经典作品。Ghiblio.art通过先进的AI算法,自动将用户上传的照片重塑为吉卜力风格的插画,赋予普通图像梦幻的动画质感。AIbase了解到,用户只需上传照片,选择吉卜力风格滤镜,平台即可在数秒内生成高质量的艺术图像。社交媒体上,用户对Ghiblio.art的操作简便性和生成效果赞不绝口,称其“仿佛将现实带入了

OpenAI CEO讨论AI艺术补偿:承认需要新模式但缺乏具体计划
在最近的TED采访中,OpenAI首席执行官Sam Altman就AI系统使用艺术家独特风格时的补偿问题提出了自己的见解,但未能提供具体解决方案。尽管OpenAI目前禁止生成模仿在世艺术家风格的图像,Altman暗示未来可能采用一种让艺术家"选择加入并获得报酬"的模式。"我认为找到一种新的模式会很酷,如果你说我想以这位艺术家的名义做这件事并且他们选择加入,那么就存在一种收入模式,"Altman表示。当TED负责人Chris Anderson提出GPT-4o可能构成知识产权盗窃时,引发观众掌声,Altman回应道:"你们可以随意

AI艺术风潮席卷吉卜力,学生们在创新与剽窃之间挣扎
近年来,吉卜力工作室风格的 AI 艺术作品在社交媒体上迅速传播,许多用户利用 AI 工具生成全新图像或重现已有照片,以展现这一日本动画工作室的独特风格。然而,这股热潮让人们不得不思考,欣赏与剽窃之间的界限究竟在哪里。自3月31日 OpenAI 为 ChatGPT 推出新功能,允许用户生成更加详细的照片后,AI 艺术的热潮随之而来。ASU 的太阳魔鬼健身中心等机构也参与其中,但很快便遭到了学生们的批评,认为这种做法剥夺了艺术家的创作价值。图源备注:图片由AI生成,图片授权服务商Midj

Reply扩大创意实验,推出AI音乐大赛与重返AI电影节
意大利都灵消息 ——Reply 公司近日宣布,出于对创新文化的追求以及对年轻一代使用新技术的热情,他们将启动一项全新的 AI 音乐大赛,并且迎回第二届 AI 电影节。这两个国际赛事旨在为创意人才提供展示自己才能的舞台,并通过人工智能来推动艺术创作的新边界。首先,Reply 与欧洲著名电子音乐节 Kappa FuturFestival 联手推出的 AI 音乐大赛,邀请年轻艺术家们在音乐中融入 AI 技术。比赛的主题为 “体验节拍”,鼓励参赛者创造五分钟的沉浸式音乐表演,结合音乐、视觉艺术和观众互动。

推理版局部重绘方法LanPaint,零训练修复图片
近日,开发者 scraed 在 GitHub 上发布了 LanPaint,一个无需额外训练的图像修复工具。该工具旨在帮助用户在任何稳定扩散模型(SD)上实现高质量的图像修复效果,甚至包括用户自己训练的自定义模型。LanPaint 通过多次迭代让模型在去噪之前 “思考”,从而获得更为无缝和准确的修复结果。LanPaint 的主要特点之一是零训练修复。用户可以立即在任何 SD 模型上使用该工具,无需进行繁琐的训练过程。此外,LanPaint 的集成十分简单,用户可以像使用标准的 ComfyUI KSampler 一样进行操作,流畅的工

佳士得首场 AI 艺术拍卖引发争议,成交额达 72.8 万美元
近日,著名拍卖行佳士得(Christies)举行了首次以人工智能(AI)为主题的艺术拍卖会,此次拍卖会名为 “增强智能”(Augmented Intelligence),在全球范围内引发了广泛的关注与争议。根据佳士得的数据显示,拍卖会共吸引了超过30件作品,最终成交额达728,784美元。图源备注:图片由AI生成,图片授权服务商Midjourney然而,这场拍卖会并非一帆风顺。在拍卖前,超过5,600名艺术家联合签署了一封公开信,要求佳士得取消此次拍卖。公开信中指出,许多参拍作品是通过未经授权的 AI 模型训练而成,

谷歌推出Imagen 3图像生成 API,每张仅需0.03美元
谷歌近日宣布,旗下最新的图像生成模型 ——Imagen3,现已通过 Gemini API 向开发者开放。这个模型不仅具备强大的图像生成能力,还能根据输入的文本提示创造出多种艺术风格的图像,涵盖从超现实主义到动漫角色的广泛范畴。Imagen3的使用非常简单,开发者只需通过 API 提交文本描述,模型便会迅速生成高质量图像。每张图像的生成成本仅为0.03美元,适合需要批量图像生成的开发者和企业。通过这一合理的定价策略,谷歌旨在降低创意工作的门槛,让更多人能够享受 AI 带来的艺术创作乐趣
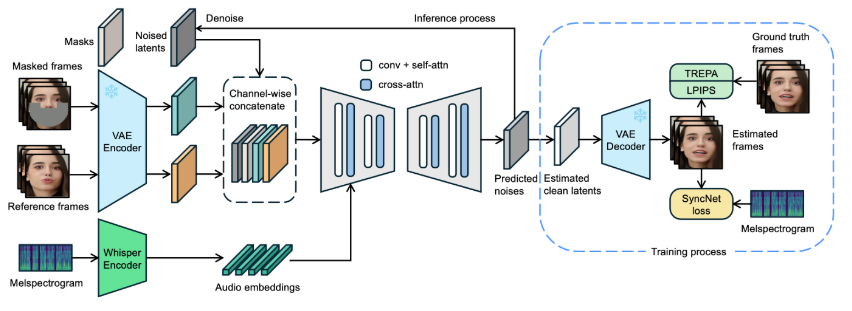
字节开源嘴型同步模型LatentSync,实现超真实口型同步
近日,字节跳动发布了名为 LatentSync 的新型口型同步框架,旨在利用音频条件潜在扩散模型实现更精确的口型同步。该框架基于Stable Diffusion,针对时间一致性做了优化。与以往的基于像素空间扩散或两阶段生成的方法不同,LatentSync 采用端到端的方式,无需中间运动表示,能够直接建模复杂的音频与视觉之间的关系。在 LatentSync 的框架中,首先使用 Whisper 将音频频谱图转换为音频嵌入,并通过交叉注意力层将其集成到 U-Net 模型中。框架通过将参考帧和掩码帧与噪声潜在变量进行通道级拼接

字节跳动开源全新AI模型LatentSync 精准控制唇形同步
字节跳动近日开源了一项名为 LatentSync 的创新技术,该技术是一种基于音频条件的潜在扩散模型的端到端唇同步框架。这项技术无需任何中间运动表示,即可实现视频中人物唇部动作与音频的精准同步。与以往基于像素空间扩散或两阶段生成的唇同步方法不同,LatentSync 直接利用了 Stable Diffusion 的强大功能,能更有效地建模复杂的视听关联。研究发现,基于扩散的唇同步方法在时间一致性方面表现不佳,因为不同帧之间的扩散过程存在不一致性。为了解决这个问题,LatentSync 引入了时间表示

Stable Diffusion 3.5 Large正式上线亚马逊 Bedrock平台
在近日的 AWS re:Invent 大会上,Stable Diffusion3.5 Large(SD3.5Large)宣布正式在亚马逊 Bedrock 平台上可用。作为 AWS 的完全托管平台,Bedrock 旨在为开发者提供构建和扩展生成式人工智能应用的基础模型。通过将 SD3.5Large 引入亚马逊 Bedrock,Stability AI 希望满足开发者在可信的 AWS 环境中进行工作和部署的需求,从而使初创企业和大型企业能够安全、便捷地使用这一先进模型,而无需担心额外的基础设施问题。Stable Diffusion3.5 Large在文本到图像生成方面表现卓越,具有多种关键能力。首先,它支持多样